#49. CI CD. Docker
Методології розробки. Git flow. CI/CD. Моноліт і мікросервіси. Docker
У цій лекції поговоримо про те, як розробка відбувається в реальності. Як розробники взаємодіють між собою,
які ще ролі бувають у команді та навіщо вони потрібні. Як найчастіше використовується git. І як при правильному підході можна
автоматизувати всі процеси деплойменту.
У досить великих компаніях процесами автоматизації займаються окремі фахівці, називаються DevOps (Development
and Operation) або навіть DevSecOps (Development, Security and Operations). Але в невеликих компаніях цим займаються самі
розробники, тому я вважаю, що нам необхідно розуміти, як це влаштовано.
Методології розроблення
Методологія розроблення ПЗ - це процес опису того, як певний продукт буде розроблятися, тобто один
зі способів організації колективного розроблення. Існує безліч різних моделей такого процесу, кожна з яких
описує свій підхід. Не можна сказати, що серед них виділяється одна, яку потрібно використовувати в кожному проєкті, все
суто ситуативно.
По суті, це правила та обов’язки співробітників під час розроблення програмного забезпечення, і які взагалі потрібні фахівці.
Насправді, їх доволі багато, я знаю щонайменше 7, але в реальності в сучасному світі я стикався тільки з 3-ю,
і то scrum дуже сильно попереду за кількістю команд, які його використовують. Давайте розбиратися.
Пропоную розглянути докладніше.
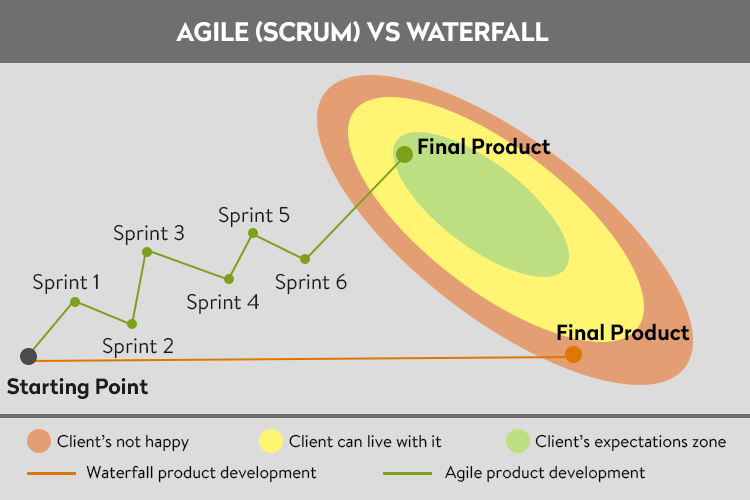
Waterfall
Waterfall, він же водоспад.
Waterfall (каскадна, водоспадна) - одна з найстаріших методологій, що передбачає сувору послідовність
виконання всіх етапів, кожен з яких має завершитися перед початком наступного. Тобто перехід на наступний етап
означає повне завершення робіт на попередньому. На зображенні показано, що спочатку ми аналізуємо завдання (документуємо
завдання, обговорюємо складнощі), потім відбувається дизайн (на цьому етапі формується структура проєкту), далі кодинг і
тестування. Повернень на наступні етапи не передбачено. Використовувати таку систему рекомендується в невеликих
проєктах, де відомі заздалегідь вимоги і мала ймовірність, що вони будуть змінюватися.

Якщо ми припустимо, що ми розробляємо автомобіль, щоб зробити це по вотерфолу, то потрібно дати чітке завдання
команді проектування, коли вся документальна робота буде закінчена, потрібно перейти до етапу дизайну і опрацювання
автомобіля, потім зібрати прототип, після чого провести тестування.
Переваги:
-
Повна та узгоджена документація на кожному етапі;
-
Простота використання;
-
Стабільні вимоги.
-
Бюджет і дедлайни заздалегідь визначені
Недоліки:
-
Велика кількість документації;
-
Не дуже гнучка система;
-
Немає можливості повернутися на крок назад.
Kanban
Канбан - система, побудована на візуалізації процесу виконання завдань команди. Основна ідея в цій системі
зменшувати кількість завдань, що виконуються на цей момент (у колонці in progress). У канбані на першому місці завдання.
Гарний для проєктів, які в стадії підтримки, де основний функціонал уже розроблений і залишилися мінімальні доопрацювання
і багофіксинг.
У канбані завдання здаються індивідуально. Завдання незалежно від інших завдань проходить усіма етапами на дошці, і як тільки
вона виконана, її можна показати замовнику.
Канбан дошка складається зі стовпчиків, кожна з яких - це окремий процес розробки. На деякі стовпці (наприклад,
in progress) вводять обмеження щодо кількості тасок, які там можуть перебувати. Це допомагає легко і швидко
знаходити проблемні місця в розподілі завдань. На зображенні приклад найпростішої такої дошки. Кількість колонок і
назви можуть змінюватися, назву найпоширеніші:

Насправді колонок може бути скільки завгодно, і вони можуть бути найрізноманітнішими.
Наприклад:
-
To do - список завдань, які треба зробити
-
In progress - завдання, над якими ведеться робота в даний момент
-
Code review - завдання, які зроблені та відправлені на рев’ю
-
In testing - завдання, готові до тестування
-
Done - зроблені завдання.
Переваги:
-
Простота використання.
-
Наочність (допомагає в знаходженні вузьких місць, спрощує розуміння)
-
Висока залученість команди в сам процес.
-
Висока гнучкість у розробленні.
Недоліки:
-
Нестабільний список завдань.
-
Складно застосовувати на довгострокових проєктах.
-
Відсутність жорстких дедлайнів.
У випадку з розробкою автомобіля це б означало, що ми мали б купу розбитих завдань, наприклад, спроектувати колесо,
продумати трансмісію тощо. І відповідальні за це люди. У реальності зустрічав тільки на саппорт проєктах. Це такі,
де все давно працює і необхідно тільки підтримувати або вносити невеликі правки. Але канбан дошка дуже і дуже
часто використовується як інструмент всередині процесу scrum, про нього і поговоримо.
Scrum
Про нього дуже детальніше.
Насправді, Scrum - це лише підвид методології, яка називається Agile.
Суть Agile полягає в його дослівному перекладі: Agile - гнучкий. Сенс полягає в тому, щоб сконцентруватися на
результаті, водночас маючи можливість гнучкого управління і правок у процесі розробки.
Як його взагалі придумали? Повернемося на сто років назад і до прикладу зі складанням автомобіля. Ми - Генрі Форд і хочемо першими
зібрати масовий, серійний автомобіль. Припустимо, ми витратили 2 роки і 2 мільйони доларів на проектну документацію,
потім 3 роки і 4 мільйони на креслення, потім 2 мільйони і 1 рік на складання
прототипу і збираємося перейти до тестування. І на етапі тестування в перший день ми з’ясовуємо, що в документації
були допущені помилки під час обчислень, і наш автомобіль перевертається на кожному повороті.
Висновок, ми витратили 6 років і 8 мільйонів на роботу, яку треба починати спочатку, тому що документацію потрібно починати
спочатку, і ми й гадки не маємо, як зміни, пов’язані з поворотами, вплинуть на решту системи.
Такий підхід нікого не влаштовував, і був придуманий Agile. Суть Agile - запровадити тимчасові цикли розробки, наприкінці яких
завжди виходить якийсь результат. Наприклад, ми вводимо цикл у 3 місяці, і кожні 3 місяці
дивимося на результати. Наприклад, у нас уже є мотор, і ми хочемо переконатися, що він зможе крутити колеса, і збираємо
тільки мотор, колеса і всі пов’язуючі їх деталі, якщо наприкінці такого циклу все добре, то йдемо далі, якщо ні - шукаємо
помилку, але ми втратили лише 3 місяці, а не 6 років. Якщо проблема виявилася на пізніших етапах, ми завжди можемо
повернутися до результатів такого циклу і подивитися лише те, що було розроблено на цьому етапі.
Такі цикли розробки називаються спринтами.

У підсумку ми отримуємо довший процес, тому що ми в будь-який момент можемо змінити цілі або деталі поточної роботи, але
при цьому дуже сильно зменшуємо бюджет через зведення глобальних помилок до нуля. Практика останніх 100 років показала,
що цей підхід практично завжди виходить значно дешевшим, якщо ви створюєте що завгодно, складніше цвяха.
З особистої практики, клієнт майже ніколи не знає, що він хоче, є тільки приблизне розуміння того, як усе має бути
бути в кінці.
Якщо в одне речення, то суть зводиться до фрази: починали робити автомобіль, у процесі створили вертоліт, а зараз
переробляємо його на підводний човен, але клієнт щасливий і платить, бо саме він йому виявився і потрібен.
Ролі в SCRUM команді
У рамках SCRUM існує три основні ролі:
- Product Owner (PO) - замовник, найчастіше це спеціально призначений менеджер, який займається постановкою завдань і
збором вимог від так званих stakeholders, у випадку великих компаній майже ніколи не буває одного
вигодонабувача, і важливо, щоб завдання ставила тільки одна людина.
- Developer Team Member - це ви. І не тільки ви, це будь-які люди, які беруть участь у процесі розробки, тестувальники,
дизайнери, бізнес-аналітики тощо. Їхня роль працювати роботу.
- Scrum Master (SM) - це ще один менеджер. Його завдання - це захист команди та відстеження дотримання SCRUM процесів, про
їх далі. Навіщо захищати команду? Тому що Product Owner завжди зацікавлений у тому, щоб команда видавала
максимальний результат, незважаючи ні на що. У такій ситуації, якби не було SCRUM майстра, то Product Owner був би
тільки радий дати завдань стільки, щоб вони займали 24/7, одне з основних завдань SM - стежити, щоб так не було.
Процеси та терміни
Що потрібно зробити, щоб організувати такий процес. Насамперед необхідно визначити зручний для вас розмір
спринту, вважається, що він має бути від 1 до 4 тижнів. Я в реальності за винятком одного проєкту працював із двох
тижневими спринтами, у тому винятку було 3 тижні. Це розмір визначають усі разом (Dev Team + PO + SM)
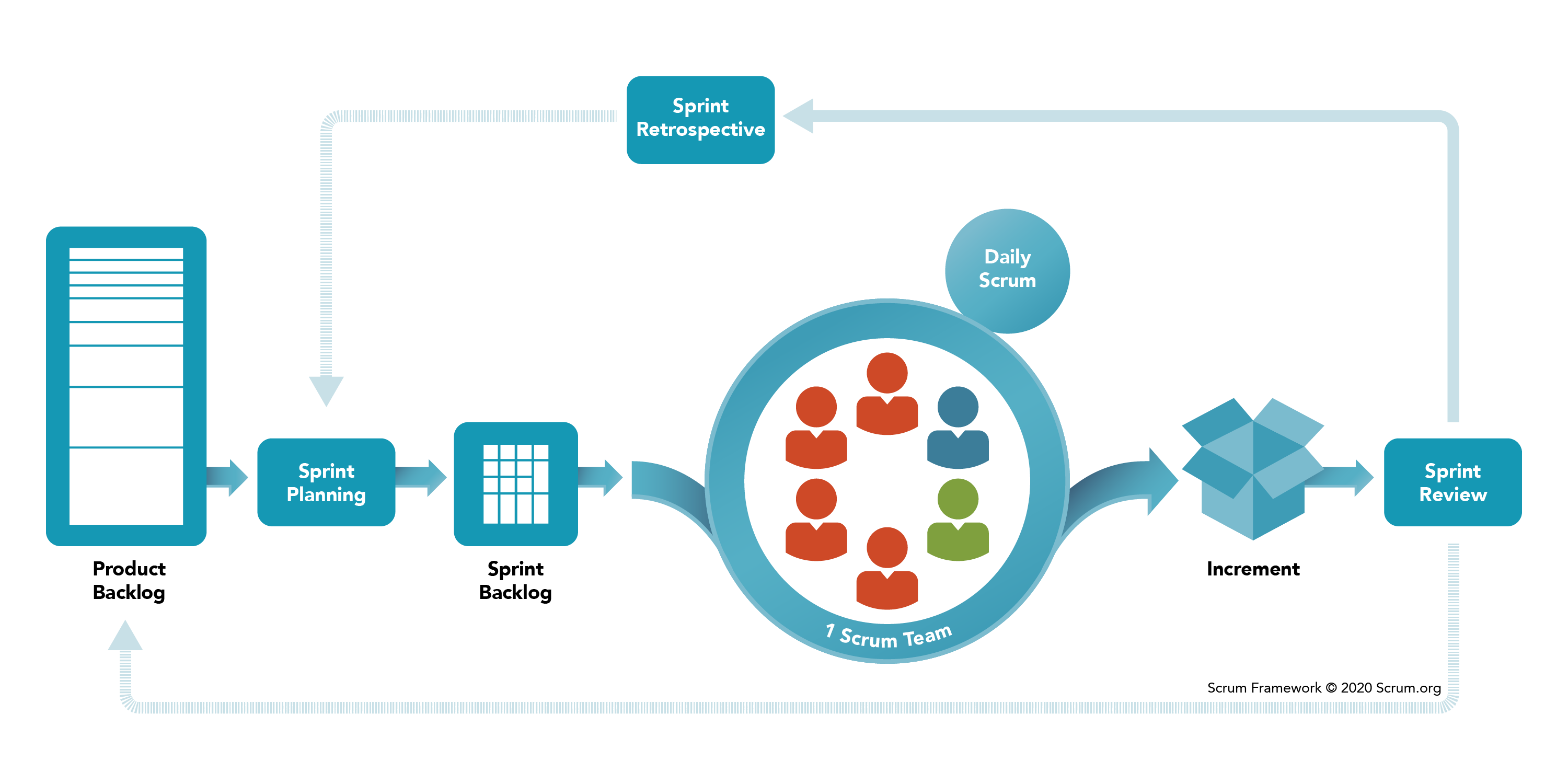
Наступний етап - це заповнення беклогу продукту.
Backlog (беклог) - це місце, де лежатимуть ваші завдання, найчастіше це різні спеціалізовані сервіси, дуже
часто це Jira або Azure Devops, але насправді їх існує дуже і дуже багато.
Беклог продукту заповнює Product Owner, чим детальніше описано завдання, тим простіше потім його виконувати, тому стежити за
деталізацією беклога - це завдання SCRUM майстра і бізнес аналітиків, якщо вони є. Бізнес аналітик - це найчастіше
перекладач з мови замовника на технічну і навпаки, дуже корисні хлопці.
В ідеальному світі, в беклозі продукту має бути завдань не менше ніж на 2 спринти.
Після чого починається процес планування спринту, зазвичай цим займається дев команда, як саме це відбувається,
обговоримо далі, поки що загальна ідея.
Результатом планування є беклог спринту, тобто список обраних завдань на наступний цикл розробки.
Коли беклог спринту готовий, починається процес розробки.
Важливим елементом розробки є щоденний мітинг усією командою. Такий мітинг може називатися по-різному: daily,
scrum, stand up тощо. Можуть бути поєднання цих слів.
Навіщо він потрібен?
На такому мітингу кожен учасник команди відповідає на 3 найголовніші запитання:
-
Що зробив?
-
Що збираєшся робити?
-
Чи немає обставин, що блокують?
Навіщо на них відповідати, сподіваюся, пояснювати не треба.
Наприкінці спринту результатом найчастіше є деплой результату, іноді просто демонстрація результатів Product
Owner. Такий мітинг називається review.
Після рев’ю обов’язково проходить ретроспектива. Це ще один мітинг, який потрібен для поліпшення SCRUM процесів.

Що це таке? Це мітинг, на якому необхідно намалювати на дошці три колонки:
-
Плюси спринту
-
Мінуси спринту
-
Дії
Перші два заповнюються учасниками команди. Кожен озвучує плюси і мінуси, які він побачив.
Якщо за плюси зазвичай просто хвалять, то мінуси потрібно розбирати.
Наприклад, плюс, що тестувальники дуже добре спрацювали і вчасно знайшли критичний баг, молодці.
А мінус, що у проєкту немає документації, припустимо, з логінами і паролями від серверів, а вони потрібні.
На кожен мінус прописується дія, у моєму прикладі - це буде, створити файл із паролями.
Далі кожен учасник команди має якусь кількість голосів, там де я працював, це найчастіше було 2. Голоси
можна віддати за ті дії, які для тебе найбільш критичні, кілька найбільш проголосованих беруться в роботу і
призначаються відповідальні. Наступна ретроспектива починається з обговорення минулих завдань і результатів.
Якщо SCRUM побудований нормально, то на перших спринтах дій дуже багато, але чим далі заходить процес, тим їх менше,
і тим більше заповнюються плюси і йдуть мінуси.
Необхідно для того, щоб допомогти самій команді в її процесах.
Разом обов’язкові мітинги:
-
Планування
-
Щоденна зустріч
-
Огляд
-
Ретроспектива
Після цього починаємо з початку, з планування спринту. І так далі
Процес планування та story points
Процес планування спринту не такий простий, як здається. Яка виникає проблема? Як зрозуміти, яка кількість і яких
завдань команда взагалі може зробити?
Щоб визначити це, вводиться спеціальне поняття, story points. Сторі поінти - це умовна складність завдання,
яка не залежить ні від ваших навичок, ні від розміру команди. Щоб зрозуміти суть, потрібно поставити собі запитання, що простіше
почистити: банан, папайю або мандарин? Найімовірніше, незалежно від своїх навичок і розміру команди ви зможете
сказати, що простіше, а що складніше.
Як цю складність визначають? Зазвичай за допомогою SCRUM покеру.
SCRUM покер
Якщо процес відбувається офлайн, то кожному учаснику команди видають картки з цифрами та символами:
[1, 2, 3, 5, 8, 13, 20, 40, 100, 'Чашка кави', 'Нескінченність']

Можуть бути варіанти, але суть завжди одна.
Беремо задачу з беклогу, обговорюємо і після обговорення всі одночасно перевертають карту, яку вважають
правильною.
Якщо ти не розумієш суті завдання, наприклад, завдання з дизайну, а ти бекенд розробник, або навпаки, то викидаєш
карту з кавою, як символ, що ти не береш участі в обговоренні цього завдання.
І нескінченність або символ ? у разі, якщо ти вважаєш, що це завдання взагалі неможливо зробити або нам не вистачає
деталей для її оцінки.
Якщо немає дуже великого розкиду, то значення обирають більшістю, наприклад 1 людина кинула 2, 3 людини - 3, і ще
один 5, то просто візьмуть 3.
А якщо хтось кидає сильно менше або сильно більше, починається обговорення і повторне голосування, можливо, цей
хтось знає простий спосіб вирішення або навпаки бачить якийсь підводний камінь.
Кожному завданню проставляється складність. Зазвичай складність вища за 20, і навіть 13 вважається занадто високою, а отже
завдання потрібно розбити на дрібніші, які будуть оцінені не вище ніж у 8. Хоча бувають і винятки.
Планування та швидкість
Коли йде перший спринт, ні ви, ні Product Owner, ні Scrum Master не знають, скільки завдань ви можете виконати,
тому береться та кількість завдань, які ви вважаєте, що ви можете зробити.
Сума всіх сторі поінтів, які ви набрали в спринт називається velocity. І за результатами першого спринту стає
зрозуміло, ви взяли багато, мало або якраз, що і можна обговорити на ретроспективі.
Перші кілька спринтів цифра може дуже сильно змінюватися від спринту до спринту, але через 3-4 спринти стає
зрозуміло, яка velocity у вашої команди.
І ґрунтуючись на цій цифрі, Product Owner і Scrum Master можуть розуміти, яка реальна кількість роботи, за яку
час зможе зробити саме ця команда.
В ідеальному світі ваша velocity має зростати, але це дуже індивідуально.
Діаграми згоряння
Важливим елементом є діаграма згоряння завдань у спринті.
Завдання в SCRUM також потрапляють на дошку завдань, де у статусів може бути різна вага.
Наприклад:
-
Потрібно зробити - 0 балів
-
У процесі - 1 бал
-
На тестуванні - 2 бали
-
На перевірці у Product Owner - 3 бали
-
Готово - 4 бали
І завдяки цим цифрам можна побудувати графік того, як саме змінюється процес виконання спринту в реальному часі.
Виглядає приблизно так:

Природно, чим ви ближче до ідеальної прямої, тим краще. І така діаграма може допомогти менеджерам стежити за процесом
виконання, а вам - зрозуміти, чи є у вас проблеми.
Доступ до такої діаграми має бути у всіх учасників команди.
Таку саму діаграму можна побудувати для всього проєкту, але на практиці її майже ніколи не роблять, тому що ніхто не
знає, скільки разів зміняться або додадуться вимоги.
Недоліки SCRUM
-
Складно оцінити трудовитрати і вартість, необхідні на розроблення
-
Складно визначити найвужчі місця до початку розробки.
-
Необхідність залучення кожного в розробку інших членів команди.
Фінал проєкту може бути дуже сильно зсунутий від планів замовника з усіх уже озвучених причин
На початку проєкту дуже багато випадкових факторів. Неправильна оцінка сил, неналагоджені процеси, немає чіткого розуміння,
як вирішувати блокери.
SCRUM передбачає, що практично кожен може замінити іншого в команді, на практиці це завжди не так, навіть у
рамках розробки, джун майже ніколи не замінить синьйора, що вже казати про те, щоб дев виконував завдання за
дизайнера. Тож складно рівномірно розподілити завдання, поки процес не “стане на рейки”.
GIT FLOW
Коли справа доходить до роботи, виникає дуже важливе питання. Як будемо використовувати GIT?
Насправді, це дуже складне питання. І на нього немає правильної відповіді.
Але якщо ми живемо в ідеальному світі, де у нас невелика команда, є профільні девопси, ми використовуємо тільки один
репозиторій, і релізи у нас виходять тільки раз наприкінці спринту, то в 2010 році за нас придумали правильну відповідь.
Відповідь називається git flow. І незважаючи на всі описані вище “або” і кількість статей з матом на цей підхід, я ще
ніколи не бачив структури, яка працювала б краще за нормальних умов.
Що ж це таке?
Якщо однією страшною картинкою, то ось:
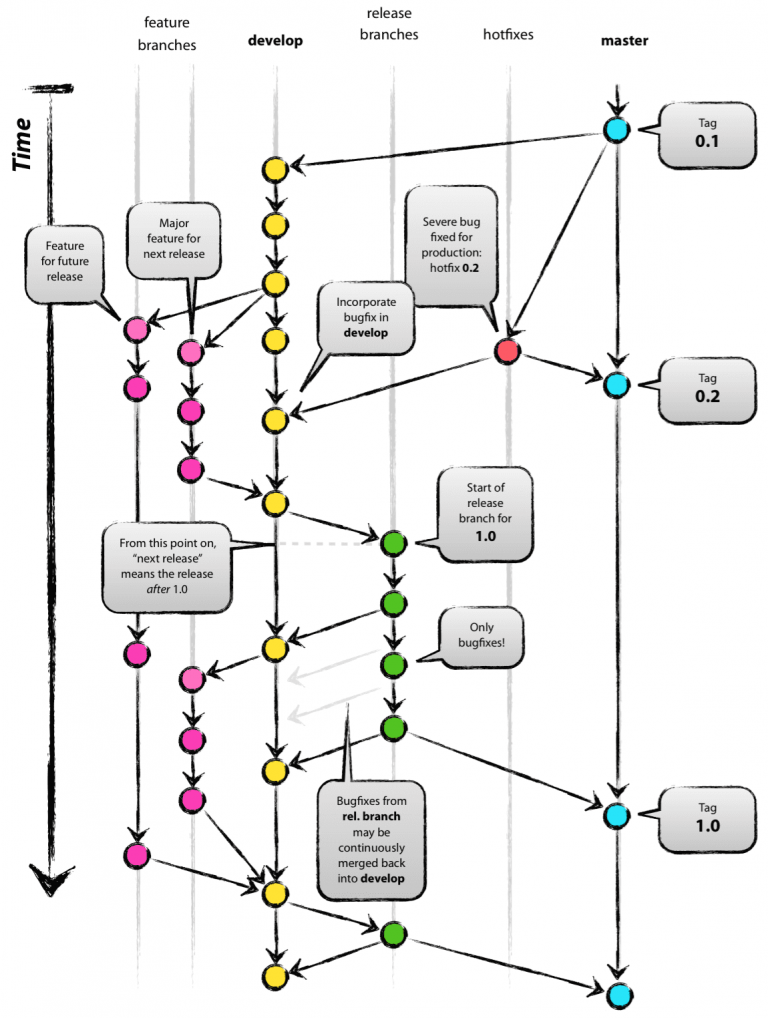
Давайте розбиратися.
За такого підходу нам необхідно дві long-term гілки. Тобто ті, які житимуть довго.
Це будуть гілки master і develop.
Якщо на пальцях, то master - це гілка, в якій завжди зберігається остання версія, яка зараз знаходиться на
продакшені (бойовому сервері, до якого є доступ у клієнтів).
А develop - це те, що зараз перебуває в розробці всією командою.
Гілка develop створюється з майстра одразу на старті проєкту, до першого комміту, але може бути створена і пізніше.
Feature
Фіча (feature) - це реалізація одного завдання з беклогу. Наприклад, додати на сайт логін, логін і буде
фічею.
За такого підходу до гіту для кожної фічі створюється окрема гілка, створюється з гілки develop.
Після завершення розробки створюється pull request у гілку develop, щоб оновити на ній поточний код.
По суті develop - це місцеве звалище всього нового коду, який тільки є.
Release
Коли команда вважає, що час віддавати фічі на тестування, з гілки develop створюється гілка release-x.x,
де x.x - це умовний номер релізу.
З неї відбувається деплоймент на тестовий сервер, де тестувальники шукають баги. Якщо баги незначні, то прямо в реліз
гілці фіксуються баги. Якщо значні, то повертаємо реліз розробникам, вони все переробляють і створюють нову гілку
релізу.
Після того як реліз гілка пройшла всі тести і готова до того, щоб оновлювати продакшен, з неї створюються два pull
request’a: на develop і на master.
На develop, щоб додати в цю гілку багофікси, якщо вони були. На master, щоб виконати деплоймент на продакшен.
На master після мерджа зазвичай створюється тег, щоб була можливість відкотити до минулого тега без особливої складності.
Hot fix
Але що робити, якщо задеплоїли продакшен і тут же виявили невеликий баг, який легко виправити? Не проходити ж усю
процедуру з початку, поки у клієнтів явно є баг?
Для цього придумали хот фікс гілки, їх створюють прямо з master, і заливають назад на master і на develop. Разом
на master, щоб задеплоїти виправлення бага, а на develop, щоб цей баг не потрапляв у нові фічі.
Висновки та реальність
Якщо для проєкту нормально застосування такого підходу, то я б дуже рекомендував його застосовувати. Але в реальності
практично завжди знаходяться проблеми, які не збігаються з таким підходом, тому дуже часто я бачив варіації на
тему git flow, ніж його сам.
Але ідея дуже крута, все структуровано зрозуміло і можливо знайти хто, що і коли.
CI/CD
CI/CD - Continuous Integration / Continuous Deployment (безперервна інтеграція / безперервне розгортання)
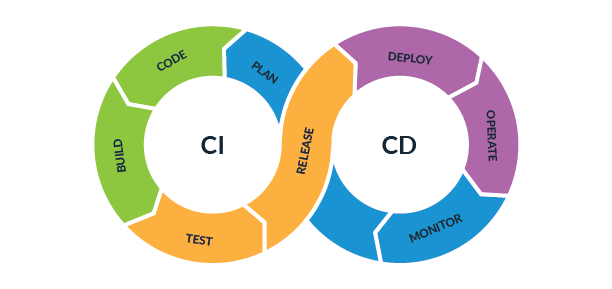
Безперервна інтеграція (Continuous Integration, CI) і безперервне постачання (Continuous Delivery, CD) являють собою
культуру, набір принципів і практик, які дають змогу розробникам частіше і надійніше розгортати зміни програмного
забезпечення.
Як це бачить розробник
У реальності, CI/CD - це можливість для розробника не замислюватися про запуск тестів і процеси деплойменту.
Зробили push і створили pull request, CI за вас запустить тести і збере ваш код у готовий для деплойменту вигляд.
Смерджили pull request, CD за вас автоматично все задеплоїть і перезапустить.
Це опис тільки однієї з конфігурацій, насправді їх може бути величезна кількість залежно від потреб
проекту.
Терміни
Безперервна інтеграція - це методологія розробки та набір практик, за яких у код вносяться невеликі зміни з
частими коммітами. І оскільки більшість сучасних застосунків розробляються з використанням різних платформ і
інструментів, то з’являється необхідність у механізмі інтеграції та тестуванні змін, що вносяться.
З технічного погляду мета CI - це спосіб забезпечити послідовний і автоматизований спосіб складання,
пакування та тестування додатків. При налагодженому процесі безперервної інтеграції розробники з більшою ймовірністю
робитимуть часті комміти, що зі свого боку сприятиме поліпшенню комунікації та підвищенню якості
програмного забезпечення.

Безперервне постачання починається там, де закінчується безперервна інтеграція. Вона автоматизує розгортання
додатків у різні оточення: більшість розробників працюють як із продакшн-оточенням, так і з середовищами
розробки та тестування.
Інструменти CI/CD допомагають налаштовувати специфічні параметри оточення, які конфігуруються під час розгортання. А
також CI/CD-автоматизація виконує необхідні запити до веб-серверів, баз даних та інших сервісів, які можуть
потребувати перезапуску або виконання якихось додаткових дій під час розгортання програми.
Безперервна інтеграція і безперервне постачання потребують безперервного тестування, оскільки кінцева мета - розробка
якісних додатків. Безперервне тестування часто реалізується у вигляді набору різних автоматизованих тестів
(регресійних, продуктивності та інших), які виконуються в CI/CD-конвеєрі.
Зріла практика CI/CD дає змогу реалізувати безперервне розгортання: у разі успішного проходження коду через
CI/CD-конвеєр, збірки автоматично розгортаються в продакшн-оточенні. Команди, які практикують безперервне постачання,
можуть дозволити собі щоденне або навіть щогодинне розгортання. Хоча тут варто зазначити, що безперервне постачання
підходить не для всіх бізнес-додатків.
Практичне застосування
Існують десятки, якщо не сотні, різних утиліт і додатків для реалізації CI/CD.
Часто замість терміна CI/CD можна побачити термін pipeline.
У всієї “великої трійки” CI/CD процеси називаються пайплайнами: AWS pipelines, Azure pipelines і GCP pipelines
відповідно.
Також неймовірно популярні Jenkins, Circle CI, Travis CI тощо. Їх дуже багато.
Ми сьогодні розглянемо налаштування CI/CD за допомогою інструменту, вшитого в GitHub, Github Actions.
Розглянемо ліву частину схеми (CI)
Plan -> Code -> Build -> Test
-
Plan - продумати, що ви хочете розробити
-
Code - написати код того, що придумали
-
Build - у нашому випадку цей степ не потрібен, оскільки Python інтерпретована мова, а Django не вимагає будь-яких
спеціальних підготовок. Але загалом цей пункт про те, що перетворити вихідний код на вигляд, придатний для деплойменту.
- Test - запустити тести
Який вигляд має в реальності?
Якщо ми дотримуємося Scrum і GitFlow, то ми протягом спринту готуємо код на гілках feature, зливаємо код у
develop, і, коли код готовий до релізу, створюємо гілку release, і з неї створюємо pull request на master. Прямий пуш
в master практично завжди заборонений. І наша система повинна автоматично після створення pull request запустити тести,
і не дозволити смерджити код, якщо тести не були успішними.
У нашому випадку ми будемо сильно спрощувати цю схему і об’єднаємо feature, develop і release. Тобто в нас буде
всього 2 гілки, гілка з новим кодом і master (Те, що ви робили у всіх домашках і модулі)
Як таке зробити за допомогою GitHub Actions?
Забороняємо прямий пуш у гілку master
Для цього на сайті GitHub переходимо в Settings -> Branches і натискаємо Add Rule.
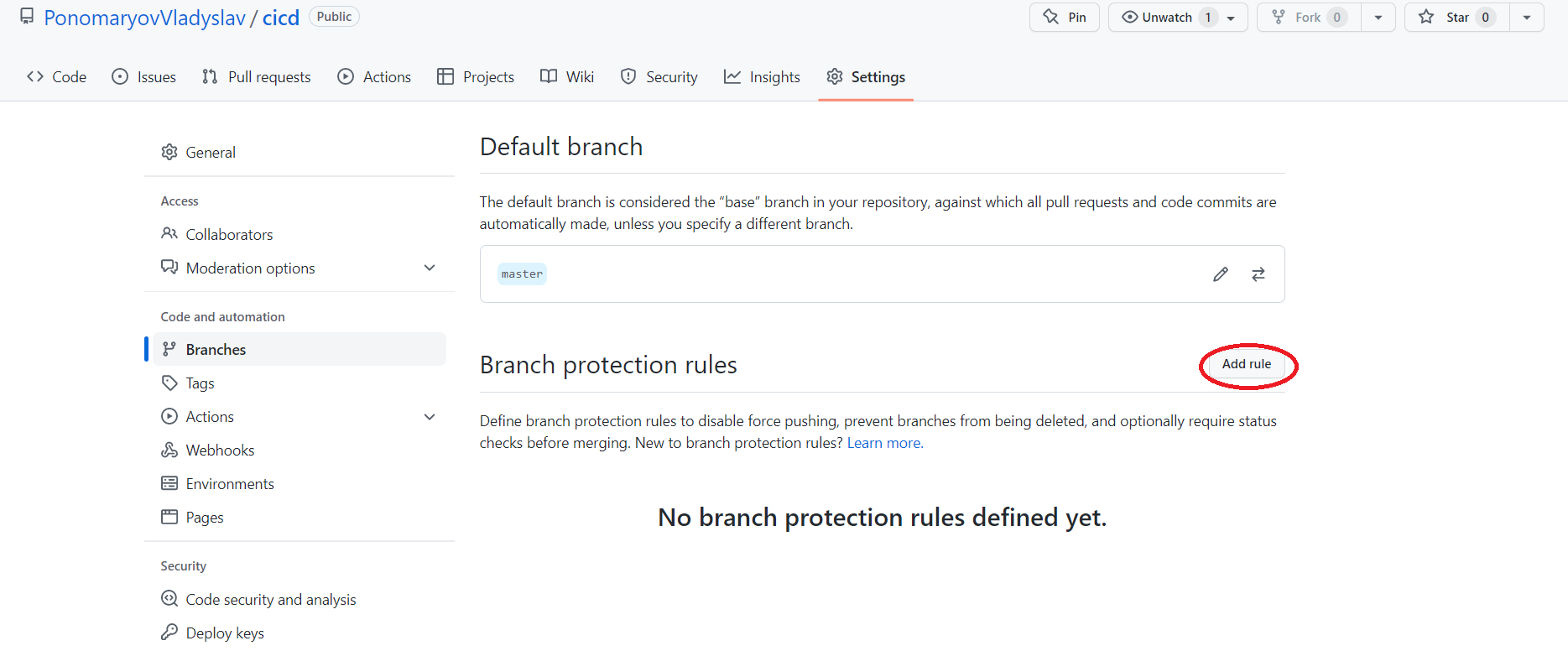
Після чого додаємо два правила для нашої основної гілки, у моєму випадку master.
-
Дозволити зміну тільки через pull request.
-
адміністратори включно, щоб ніхто не міг змінити гілку, не через pull request.
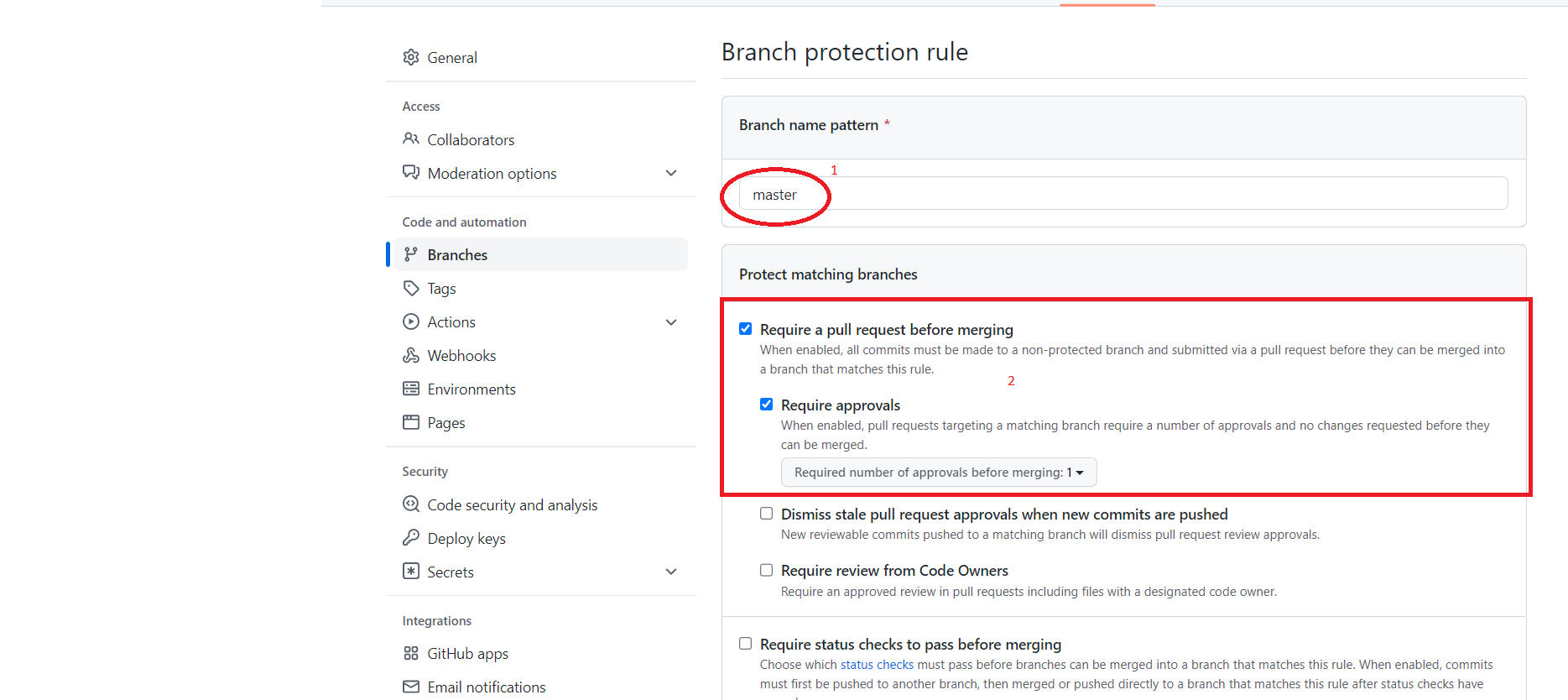

Натискаємо CREATE
Додаємо GITHUB Action
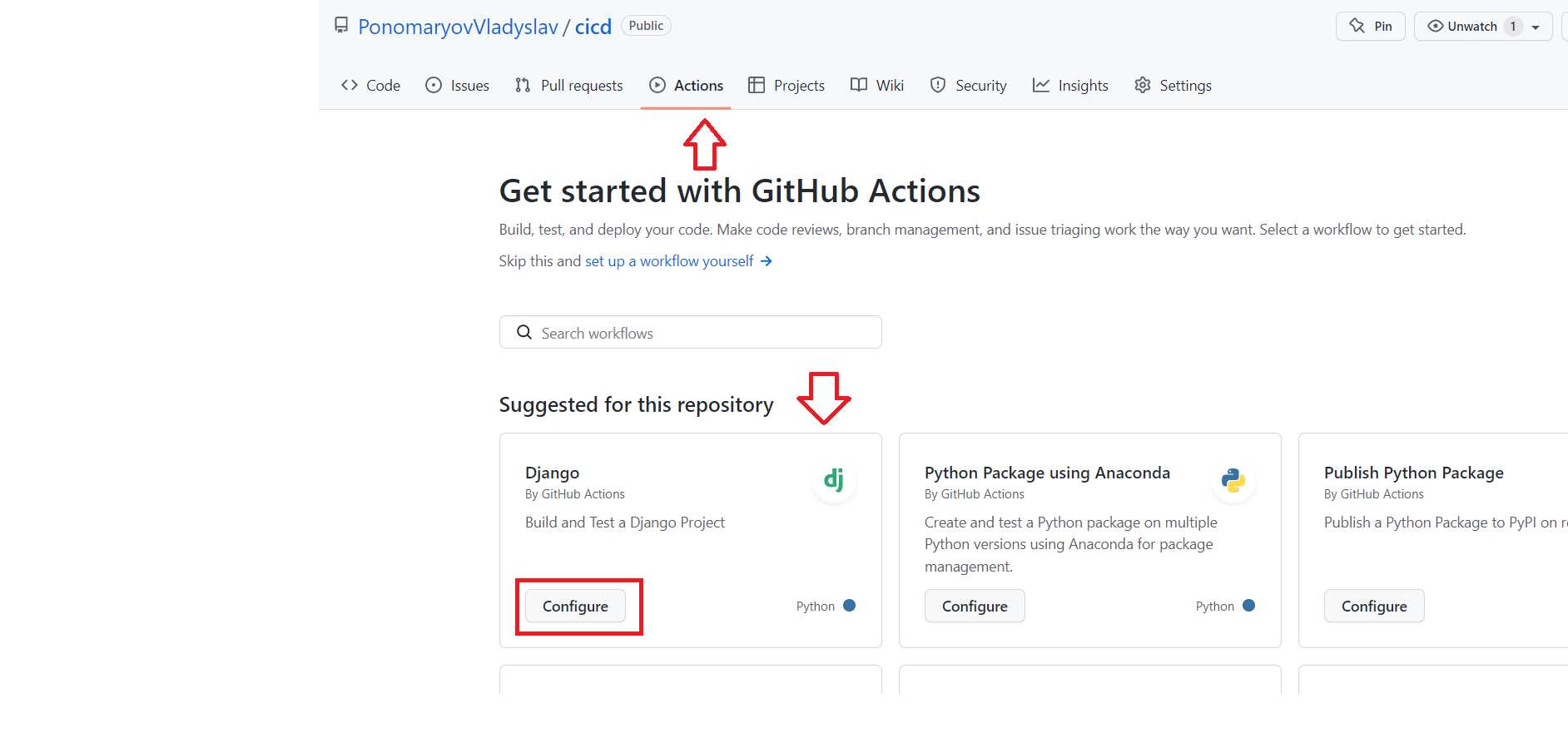
Заходимо в розділ Actions, GitHub автоматично запропонує нам додати конфігурацію для Django, якщо ви залили проект
без помилок у структурі.
Якщо автоматично не запропонує, то завжди можна знайти в пошуку.
При натисканні кнопки Configure GitHub запропонує нам додати файл .github/workflows/django.yml, причому назва файлу
можна поміняти, а шлях ні, тому що, як ми вже знаємо, .github - це прихована папка з погляду лінукса, а
workflow - папка, в якій GitHub шукатиме файли конфігурації CI.
Стандартний файл django.yml:
name: Django CI
on:
push:
branches: [ "master" ]
pull_request:
branches: [ "master" ]
jobs:
build:
runs-on: ubuntu-latest
strategy:
max-parallel: 4
matrix:
python-version: [ 3.7, 3.8, 3.9 ]
steps:
- uses: actions/checkout@v3
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v3
with:
python-version: ${{ matrix.python-version }}
- name: Install Dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Run Tests
run: |
python manage.py test
Давайте розглянемо цей файл.
name - назва, тут може бути що завгодно
on - команда, яка описує, коли має виконуватися поточна конфігурація, за дефолтом - це push у гілку майстер,
або pull request на master, оскільки ми вже заборонили push на master, цей пункт можна видалити
jobs - опис самих виконуваних команд
build - просто назва, тут можна було написати що завгодно
matrix/python-version - список версій Python, на яких необхідно запускати команди, пропоную залишити тільки 3.9
steps - виконувані кроки та залежні модулі. У нашому прикладі використовується два додаткових
модуля actions/checkout@v3, actions/setup-python@v3. Перший для взаємодії з pull request, другий для запуску
Python. І самі команди, оновити pip, запустити установку requirements.txt і запуск команди python manage.py test.
Весь цей процес запуститься на віртуальній машині, що належить GitHub, але нам це й не важливо, головне, що ми отримаємо
результат виконання тестів, і якщо тести не пройдуть, то ми не зможемо смерджити pull request.
Після наших невеликих змін ми отримаємо такий файл:
name: Django CI
on:
pull_request:
branches: [ "master" ]
jobs:
build:
runs-on: ubuntu-latest
strategy:
max-parallel: 4
matrix:
python-version: [ 3.9 ]
steps:
- uses: actions/checkout@v3
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v3
with:
python-version: ${{ matrix.python-version }}
- name: Install Dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Run Migrations # run migrations to create table in side car db container
run: python manage.py migrate
- name: Run Tests
run: |
python manage.py test
Зберігаємо. Якщо ми додали неможливість прямого коміту в master, то GitHub запропонує нам створити нову гілку і pull
request, не забудьте його смерджити!!!
По суті, в максимально простому вигляді CI степ уже налаштований, і для певних умов буде навіть працювати.

Але чого тут не вистачає? Налаштування бази даних! Адже для запуску тестів практично завжди необхідна база даних!
Давайте додамо її в налаштування.
Насамперед нам необхідно додати базу в опис запуску флоу. І додати степ із міграцією нашої бази.
name: Django CI
on:
pull_request:
branches: [ "master" ]
jobs:
build:
runs-on: ubuntu-latest
services:
postgres: # we need a postgres docker image to be booted a side car service to run the tests that needs a db
image: postgres
env: # the environment variable must match with app/settings.py if block of DATABASES variable otherwise test will fail due to connectivity issue.
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
POSTGRES_DB: github-actions
ports:
- 5432:5432 # exposing 5432 port for application to use
# needed because the postgres container does not provide a healthcheck
options: --health-cmd pg_isready --health-interval 10s --health-timeout 5s --health-retries 5
strategy:
max-parallel: 4
matrix:
python-version: [ 3.9 ]
steps:
- uses: actions/checkout@v3
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v3
with:
python-version: ${{ matrix.python-version }}
- name: Install Dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Migrate
run: python manage.py migrate
- name: Run Tests
run: |
python manage.py test
У параметрі env можна побачити налаштовані юзер, пароль і назву бази.
Зверніть увагу на параметр options, він потрібен, щоб ми виконували всі команди тільки після того, як postgres
завантажиться.
Також нам необхідно переконатися, що у нас в requirements.txt вказано psycopg2.
І внести зміни в settings.py:
if os.getenv('GITHUB_WORKFLOW'):
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'github-actions',
'USER': 'postgres',
'PASSWORD': 'postgres',
'HOST': 'localhost',
'PORT': '5432'
}
}
else:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': os.getenv('DB_NAME'),
'USER': os.getenv('DB_USER'),
'PASSWORD': os.getenv('DB_PASSWORD'),
'HOST': os.getenv('DB_HOST'),
'PORT': os.getenv('DB_PORT')
}
}
Зверніть увагу, змінна GITHUB_WORKFLOW буде додана автоматично під час запуску.
Тепер наш CI повністю готовий до роботи!
Тепер розглянемо праву частину схеми (CD)
Release -> Deploy -> Operate -> Monitor
-
Release - випустити продукт. По суті, коли код опинився в гілці
master, продукт релізнуть. -
Deploy - завантаження і розгортання коду на сервері.
-
Operate - провести всі необхідні для роботи операції, в нашому випадку, перезібрати статику і перезапустити NGINX і gunicorn.
-
Monitor - переконатися, що дії успішні. У нашому випадку просто оновити сайт і побачити, що все добре.
Насправді для того, щоб зібрати CD, і в GitHub, і в практично будь-якого іншого інструменту існує велика кількість кількість різних уже вбудованих інструментів, але оскільки зараз ми хочемо зробити все наочно, то і всі команди я пропишу вручну.
Небажано використовувати такий спосіб на реальних проєктах, це тільки демонстрація логіки!!!
Для того, щоб змусити GitHub виконувати CD, ми створимо ще один воркфлоу, який матиме приблизно такий вигляд:
name: Django CD
on:
push:
branches: [ "master" ]
jobs:
deploy:
runs-on: ubuntu-latest
strategy:
max-parallel: 4
matrix:
python-version: [ 3.9 ]
steps:
- name: deploy command
uses: JimCronqvist/action-ssh@master
with:
command: |
source venv/bin/activate
cd project_name; git pull
python manage.py collectstatic --no-input
sudo systemctl restart gunicorn; sudo systemctl restart nginx
hosts: ${{ secrets.HOST }}
privateKey: ${{ secrets.PRIVATE_KEY}}
Давайте розбиратися, що саме робитиме такий файл.
Спрацьовувати він буде на push на гілку master. Але ми ж заборонили push у гілку? Прямий так, але при мерджі пулл реквесту
виконується точно такий самий пуш. А значить, цей ворк флоу буде спрацьовувати при мержі нашого пулл реквесту, що нам і
потрібно.
Назва нової job - deploy, просто щоб зручно було читати логи.
Ми запускатимемо Python команди, а отже, нам знадобиться розділ strategy, точно такий самий, як для CI.
І додамо один єдиний крок, який виконає низку команд одразу на нашому сервері. Взагалі це не найкраще рішення, але
для наочності, це найзручніший спосіб продемонструвати CD.
Ми скористаємося стороннім модулем JimCronqvist/action-ssh.
Як параметри передамо command, hosts, privateKey.
hosts - параметр, у якому ми вкажемо, куди саме потрібно підключатися (у нашому випадку url, який видає нам Amazon)
privateKey - закритий ключ, який видав нам Amazon під час створення сервера.
Зверніть увагу, в обох випадках як значення я вказую ${{ secrets.VAR_NAME }}, що це таке?
Це змінні для Github-actions, ми ж не хочемо показувати шлях до нашого сервера, або тим більше ключі від нього,
конфігураційний файл все ще лежить у репозиторії.
Як їх створити?
Settings > Secrets > Action - і там можна створювати змінні.
І давайте розберемо, які команди я вказав виконати.
source venv/bin/activate
cd project_name; git pull
python manage.py collectstatic --no-input
sudo systemctl restart gunicorn; sudo systemctl restart nginx
-
активувати віртуальне оточення, оскільки ми збираємося збирати статику через
manage.py, цей крок нам необхідний -
Перейти в папку з проєктом і спулити останні зміни
-
Зібрати статику, параметр
--no-inputдозволить зробити це без додаткових підтверджень -
Перезапустити сервіси Nginx і Gunicorn
Назву проекту і шлях до віртуального оточення можна було також приховати через SECRETS.
Мердж пулл реквесту - це release.
Кроки 1-2 - це deploy.
Кроки 3-4 - це operate.
Залишається тільки monitor, у нашому випадку ми зробимо це руками.
Створимо будь-які видимі зміни (наприклад, поміняти щось у html або замінити статичний файл), у новій гілці,
припустимо cicd_test.
Створимо pull request, подивимося, як GitHub не дасть нам змоги смерджити його, доки не пройде крок із тестами.
Смерджим після успішних тестів.
У розділі actions подивимося, як виконується деплой, після чого перевіримо, що зміни дійсно набули чинності.
Радіємо, що найпростіший CI/CD працює.

Не забуваємо, що це тільки одна з тисяч можливих конфігурацій, до того ж не найвдаліша, насправді ще й така, що не враховує
багато потрібних деталей і подробиць! У великих компаніях усім цим налаштуванням займаються окремі люди, їхні
називають DevOps, скорочення від Development and Operation, а ще бувають DevSecOps - Development Secure Operation.
Але в невеликих компаніях усе це налаштування теж на вас :)
Моноліти та мікросервіси
Настав час поговорити про архітектуру.

І ні, ми будемо говорити не про будівлі та урбаністику.
Під архітектурою в цьому контексті я маю на увазі архітектуру побудови технічного рішення.

Під монолітом зазвичай мається на увазі технічне рішення, зібране на одному стеку технологій, яке розгортається цілком,
одним великим пакетом.
Коли ви розробляли Django додаток, ви розробляли моноліт, самі про те не здогадуючись.
А як буває ще?
Як можна здогадатися із заголовка, ще бувають мікросервіси. Що ж це таке?
Це коли у нас будь-які мінімальні дії розбиті на маленькі сервіси, і вони між собою не залежні одна від одної.
Візьмемо як приклад звичайний інтернет магазин. Припустимо, ми вже купили базу даних у Amazon, а Redis сервіс у
Google.
Як розбити завдання на мікросервіси? Наприклад, у нас може бути окремий сервіс (застосунок), який відповідає за логін.
Окремий додаток, який повертає список товарів. Окремий додаток, який дає змогу взаємодіяти з
особистим кабінетом. Окремий сервіс, що відповідає за розсилку реклами та новин, і окремий сервіс, який обробляє
платежі.
Навіщо таке робити і який у цьому сенс? Припустимо, ви зібрали моноліт із таким самим функціоналом. І раптом з’ясовується, що
подивитися на товари заходять сотні тисяч людей, а рештою функціоналу майже ніхто не користується. Щоб витримати
навантаження, необхідно розширювати весь моноліт, що може бути дуже дорого, і набагато дешевше для одного окремого
сервісу. Це лише один із прикладів, давайте пройдемося по всіх плюсах і мінусах таких архітектур.
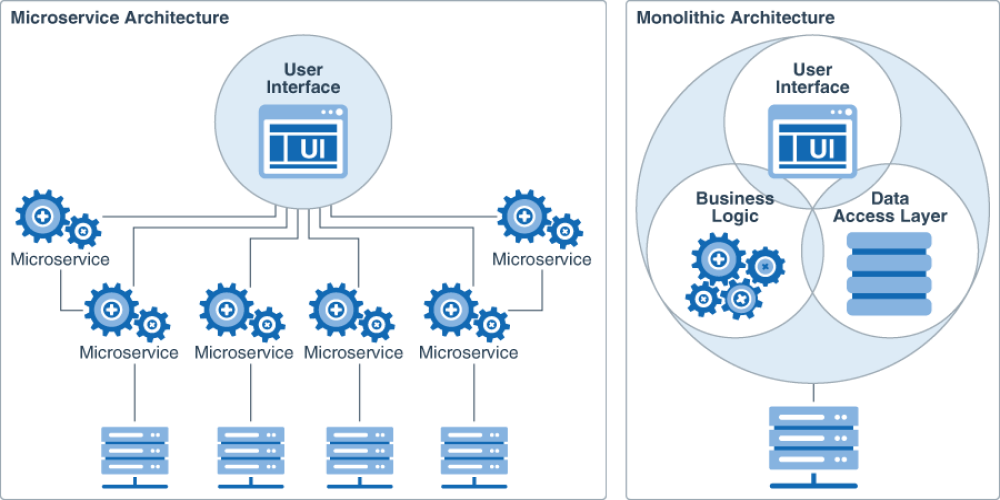
Плюси мікросервісів
У такої архітектури досить багато плюсів
Масштабованість
Як я вже описував у прикладі раніше, за такого підходу ми легко можемо збільшити ресурси для одного сервісу і прибрати для
іншого, але це ще не все.
Через те, що мікросервіси можуть взагалі бути не пов’язані технологіями, у нас може бути один модуль написаний на Python, другий
на Go, а третій на Java.
А це означає, що можна розподіляти розробників залежно від необхідності конкретного сервісу (найняти два
джавіста, і звільнити пітоніста)
Легковажність
Кожен мікросервіс при розробці завжди буде меншим за розміром, ніж моноліт, а значить, що буде деплоюватися швидше,
проганяти тести швидше тощо. Що дає змогу значно прискорити операційні питання.
Оновлюваність і незалежність
Якщо у нас є застарілий моноліт, і ми хочемо оновити його на нову версію мови або технологію, зазвичай це
нестерпний, болісний процес.
У мікросервісному підході в цьому немає проблеми, логін може бути написаний на застарілій Java, а платіжна система на самому
новому Python, припустимо на FastAPI.
Якщо ми хочемо щось оновити або переписати іншою мовою, нам достатньо виправити тільки один модуль і ніяк не
чіпати інші.
Ще одним плюсом є не пов’язаність між собою цих модулів. Не може вийти такої ситуації, коли поправили
один рядок коду, а зачепили 5 додатків. А отже, не треба писати купу нових тестів, що економить час.
Ізольованість
Якщо з якоїсь причини у нас відпаде сервіс, який розсилає рекламу, від цього весь проєкт працювати не перестане,
за монолітного підходу це не так.
Читабельність і онбординг
Набагато простіше розібратися в сервісі, який займається одним процесом, ніж вивчати величезне скупчення коду, хоч під час
переході в іншу команду, хоч приходячи з вулиці.
Та й загалом моноліт дуже часто з часом переростає в нечитабельне “місиво”.
Мінуси мікросервісів
Мінусів теж вистачає :)
E2E Тести
Коли нам потрібно провести End-2-End тестування якоїсь фічі, це може бути проблемним через те, що одна бізнес-індустрія
завдання може вирішуватися через велику кількість сервісів.
Транзакції
Дуже складно контролювати транзакції, коли процес проходить одразу в багатьох мікросервісах, особливо коли кілька
з них працюють над одними й тими самими даними.
Оновлення
Якщо потрібно внести якісь глобальні оновлення, дуже високий шанс, що необхідно буде координувати кілька
команд, а це часто буває великою проблемою.
Багато DevOps
Для підтримки таких процесів часто потрібен великий штат із девопсів, щоб вони відповідали за окремі розгортання
окремих процесів.
Висновок
Правильної відповіді, яку архітектуру використовувати, зазвичай не існує, є свої плюси і мінуси. У сучасному світі
частіше все-таки зустрічаються мікросервіси, але це не заважає, наприклад, Instagram працювати як моноліт. В ідеалі залиште
питання архітектури для архітекторів, якщо є така можливість.
Docker
Хто такий докер?

Docker - один із найвідоміших інструментів для роботи з контейнерами.
Давайте розберемося, хто такі контейнери.
Контейнери - це спосіб стандартизації розгортання застосунку та відокремлення його від загальної інфраструктури. Примірник
програми запускається в ізольованому середовищі, що не впливає на основну операційну систему.
Розробникам не потрібно замислюватися, в якому оточенні працюватиме їхній застосунок, чи будуть там потрібні налаштування і
залежності. Вони просто створюють застосунок, упаковують усі залежності та налаштування в деякий єдиний образ. Потім цей
образ можна запускати на інших системах, не турбуючись, що додаток не запуститься.
Docker - це платформа для розробки, доставки та запуску контейнерних додатків. Docker дає змогу створювати
контейнери, автоматизувати їхній запуск і розгортання, управляє життєвим циклом. Він дає змогу запускати безліч
контейнерів на одній хост-машині.
Docker вирішує проблеми залежностей і робочого оточення
Контейнери дають змогу упакувати в єдиний образ додаток і всі його залежності: бібліотеки, системні утиліти та файли
налаштування. Це спрощує перенесення програми на іншу інфраструктуру.
Наприклад, розробники створюють додаток у системі розробки - там усе налаштовано, додаток працює. Коли він
готово, його потрібно перенести в систему тестування, а потім у продуктивне середовище. Якщо в одному з них немає потрібної
залежності, додаток не працюватиме. Програмістам доведеться відволіктися від розробки і спільно з командою
підтримки розібратися в ситуації.
У контейнерах такої проблеми немає, оскільки вони містять у собі все необхідне для запуску програми. Фахівці
займаються розробкою, а не вирішенням інфраструктурних проблем.
Ізоляція та безпека
Контейнер - це набір процесів, ізольованих від основної операційної системи. Додатки працюють тільки всередині
контейнерів і не мають доступу до основної операційної системи. Це підвищує безпеку застосунків: вони не зможуть
випадково або навмисне нашкодити основній системі. Якщо додаток у контейнері завершиться з помилкою або зависне, це
ніяк не торкнеться основної ОС.
Прискорення та автоматизація розгортання додатків і масштабованість
Контейнери спрощують розгортання додатків. У класичному підході для встановлення програми потрібно зробити кілька
дій: виконати скрипт, змінити файли налаштувань тощо. У цьому процесі не виключена ймовірність людської
помилки: користувач запустить скрипт двічі, переплутає послідовність або щось не зрозуміє. Контейнери дають змогу
повністю автоматизувати цей процес, оскільки містять у собі всі потрібні залежності та порядок виконання дій.
Також контейнери спрощують розгортання на кількох серверах. У класичному підході для того, щоб розгорнути одне і
той самий застосунок на кількох машинах, потрібно буде повторювати одні й ті самі дії. Контейнери позбавляють від цієї
рутинної роботи і дають змогу автоматизувати розгортання.

Контейнери наближають до мікросервісної архітектури
Контейнери добре вписуються в мікросервісну архітектуру. Це підхід до розробки, за якого додаток розбивається на
на невеликі компоненти, по можливості незалежні. Зазвичай протиставляється монолітній архітектурі, де всі частини
системи сильно пов’язані одна з одною.
Це дає змогу розробляти нову функціональність швидше, адже у випадку з монолітною архітектурою зміна якоїсь
частини може зачепити всю іншу систему.
Docker compose - одночасно розгорнути кілька контейнерів
Docker-compose дає змогу розгортати та налаштовувати кілька контейнерів одночасно. Наприклад, для веб-додатку
потрібно розгорнути стек LAMP: Linux + Apache, MySQL, PHP. Кожен із застосунків - це окремий контейнер для ОС Linux. Але
у цій ситуації нам потрібні саме всі контейнери разом, а не окремо взятий застосунок. Docker-compose дає змогу
розгорнути і налаштувати всі додатки однією командою, а без нього довелося б розгортати і налаштовувати кожен
контейнер окремо.
Зберігання даних у Docker
Одна з головних особливостей контейнерів - ефемерність. Це означає, що контейнери можуть бути в будь-який момент
зупинені, перезапущені або знищені. При цьому всі накопичені дані в контейнері будуть втрачені. Тому
додатки потрібно розробляти так, щоб вони не покладалися на сховище даних у контейнері, це називається принципом
Stateless.
Це добре підходить для додатків або сервісів, які не зберігають результати своєї роботи. Наприклад, функції розрахунку
або перетворення даних: їм на вхід надійшов один набір даних, вони його перетворили або розрахували і повернули
результат. Усе, нічого нікуди зберігати не потрібно.

Але далеко не всі додатки такі, і є багато даних, які потрібно зберегти. У контейнерах для цього передбачені
кілька способів.
Тому я рекомендую використовувати зовнішні бази даних для реальної розробки, адже неважливо звідки буде запит, з
локалі, сервера або докера.
Архітектура (компоненти) Docker
Демон Docker
Це деякий резидентний процес, який запущено на хост-машині постійно. Він володіє всією інфраструктурою, а також
надає інтерфейс взаємодії з контейнерами, що охоплює створення і видалення, запуск і зупинку.
У ранніх версіях платформи Docker можна зустріти згадку про dockerd, але на поточний момент демони вже встигли розбитися
на окремі проєкти. Дедалі частіше можна зустріти його сучасника - containerd.
Docker client (клієнт)
Це інтерфейс командного рядка для управління Docker daemon. Ми користуємося цим клієнтом, коли створюємо і розгортаємо
контейнери, а клієнт надсилає ці запити в Docker daemon.
Docker-образ (образ)
Це незмінний файл (образ), з якого розгортаються контейнери. Додатки упаковуються саме в образи, з
яких потім уже створюються контейнери. У технічній літературі можна також зустріти опис image як шаблону
запуску процесу.
Наведемо аналогію на прикладі встановлення операційної системи. У дистрибутиві (образі) ОС є все, що необхідно для її
установки. Але цей образ не можна запустити, для початку його потрібно “розгорнути” в готову ОС. Так от, дистрибутив для
встановлення ОС - це образ, а встановлена і працююча ОС - це контейнер. Але контейнери зазвичай розгортаються однією
командою - це набагато простіше і швидше, ніж встановлення ОС.
Docker container (контейнер)

Це вже розгорнутий з образу застосунок, який працює.
Docker Registry

Це репозиторій з образами. Розробники створюють образи своїх програм і викладають їх у репозиторій, щоб їх можна було
було завантажити та скористатися ними. Поширений публічний репозиторій - Docker Hub. У ньому зібрані образи безлічі
популярних програм або платформ: бази даних, веб-сервери, компілятори, операційні системи тощо. Також можна
створити свій приватний репозиторій, наприклад, усередині компанії. Розробники розміщуватимуть там образи, які будуть
використовуватися всією компанією.
Dockerfile
Dockerfile - це інструкція для складання образу. Це простий текстовий файл, що містить по одній команді в кожному рядку.

У ньому вказуються всі програми, залежності та образи, які потрібні для розгортання образу.
Приклад:
FROM python:3
COPY main.py /
CMD [ "python", "./main.py" ]
Перший рядок означає, що за основу ми беремо образ із назвою Python версії 3 - це називається базовий образ. Docker
знайде його в docker registry, завантажить і буде використовувати за основу. Другий рядок означає, що потрібно скопіювати
файл main.py у корінь файлової системи контейнера. Третій рядок означає, що потрібно запустити Python і передати йому в
як параметр назву файлу main.py.
Основні команди
-
Команда
docker buildчитає dockerfile і збирає образ. -
Команда
docker pullзавантажує образ із docker registry. За замовчуванням, docker завантажує образи з публічного
репозиторію Docker Hub. Але можна створити своє сховище і налаштувати docker, щоб він працював із ним.
- Команда
docker runбере образ і запускає з нього контейнер.
Docker compose
Docker Compose - це можливість запустити кілька контейнерів одночасно і залежно один від одного.
Саме в такий спосіб запускається більшість проєктів, оскільки одного образу зазвичай недостатньо.
Наприклад, нам необхідно відразу запустити gunicorn, nginx, postgres.
На жаль, як використовувати докер для деплойменту Django додатка, наприклад, на Amazon, настільки величезна тема,
що мені не вистачило б і 3 заняття, тож давайте розберемо, що встигнемо за готовими статтями. А вивчити це детально, я
пропоную вам самостійно:
Статті:
Докер, джанго, let’s encrypt і деплоймент на AWS