#42. Multithreading, Multiprocessing, GIL
Multithreading, Multiprocessing, GIL

Потоки
Щоб зрозуміти багатопоточність, спочатку вникнемо, що таке процес.
Процес - це частина віртуальної пам’яті та ресурсів, яку ОС виділяє для виконання програми. Якщо відкрити кілька екземплярів одного додатка, то під кожен система виділить окремий процес. У сучасних браузерах за кожну вкладку може відповідати окремий процес.
Ви напевно стикалися з “Диспетчером завдань” у Windows (у Linux - “Системний монітор”) і знаєте, що зайві запущені процеси вантажать систему, а “найважчі” з них бувають і зависають, тож їх доводиться завершувати примусово.
Але користувачі люблять багатозадачність: тільки дай відкрити з десяток вікон і поперемикатися між ними. У наявності дилема: потрібно забезпечити одночасну роботу додатків і при цьому знизити навантаження на систему, щоб вона не гальмувала. Припустимо, “залізу” не встигнути за потребами власників - потрібно вирішувати питання на програмному рівні.
Ми хочемо, щоб за одиницю часу процесор встигав виконати більше команд і обробити більше даних. Тобто нам треба вмістити в кожному кванті часу більше виконаного коду.
Уявіть одиницю виконання коду у вигляді об’єкта - це і є потік.
До складної справи легше підступитися, якщо розбити її на кілька простих. Так і при роботі з пам’яттю: “важкий” процес ділять на потоки, які займають менше ресурсів і швидше доносять код до обчислювача.
У кожного додатку є щонайменше один процес, а в кожного процесу - щонайменше один потік, який називають головним, і з якого за необхідності запускають нові.

Різниця між потоками та процесами
-
Потоки використовують пам’ять, виділену під процес, а процеси вимагають собі окрему місце в пам’яті. Тому потоки створюються і завершуються швидше: системі не потрібно щоразу виділяти їм нове адресне простір, а потім вивільняти його.
-
Процеси працюють кожен зі своїми даними - обмінюватися чимось вони можуть тільки через механізм міжпроцесної взаємодії. Потоки звертаються до даних і ресурсів один одного безпосередньо: що змінив один - одразу доступно всім. Потік може контролювати “побратимів” по процесу, тоді як процес контролює виключно своїх “дочок”. Тому перемикатися між потоками швидше і комунікація між ними організована простіше.
Який звідси висновок? Якщо вам потрібно якомога швидше обробити великий обсяг даних, розбийте його на шматки, які можна обробляти окремими потоками, а потім зберіть результат воєдино. Це краще, ніж плодити жадібні до ресурсів процеси.
Але чому такий популярний застосунок, як Firefox, йде шляхом створення кількох процесів? Тому що саме для браузера ізольована робота вкладок - це надійно і гнучко. Якщо з одним процесом щось не так, необов’язково завершувати програму цілком - є можливість зберегти хоча б частину даних.
Що таке багатопоточність? Ось ми й підійшли до головного.
Багатопоточність - це коли процес програми розбитий на потоки, які паралельно - в одну одиницю часу - обробляються процесором.
Обчислювальне навантаження розподіляється між двома або більше ядрами, так що інтерфейс та інші компоненти програми не уповільнюють роботу один одного.
Багатопотокові додатки можна запускати і на одноядерних процесорах, але тоді потоки виконуються по черзі: перший попрацював, його стан зберегли - дали попрацювати другому, зберегли - повернулися до першого або запустили третій, і тощо.
Multithreading (Багатопоточність)

Що таке потік?
Потік (англ. thread) або повніше потік виконання (англ. thread of execution), — це найменша послідовність запрограмованих інструкцій, якими може незалежно керувати планувальник, який зазвичай є частиною операційної системи. У багатьох випадках потік є компонентом процесу.
Потік - це спосіб програми розділити себе на дві чи більше паралельні задачі. Реалізація потоків та процесів відрізняються в різних операційних системах, але загалом потік міститься всередині процесу і різні потоки одного процесу спільно розподіляють деякі ресурси, у той час як різні процеси ресурси не розподіляють.
У системах з одним процесором багатопотоковість реалізується загалом поділом часу виконання («кванти часу»), дуже подібно до паралельного виконання багатьох задач: процесор послідовно переключається між різними потоками. Це переключення контексту відбувається настільки швидко, що в кінцевого користувача створюється ілюзія одночасного виконання. На багатопроцесорних чи на багатоядерних системах робота потоків здійснюється справді одночасно, оскільки різні потоки і процеси виконуються буквально одночасно різними процесорами або ядрами процесора.
Про потоки потрібно знати таке:
- Вони існують усередині процесу;
- В одному процесі може бути кілька потоків;
- Потоки в одному процесі поділяють стан і пам’ять батьківського процесу.
- Потоки працюють паралельно.
threading

У Python існує вбудований модуль threading, найпростішим прикладом використання буде наступний код:
import time
from threading import Thread
def sleep_me(i):
print("Потік %i засинає на 5 секунд.\n" % i)
time.sleep(5)
print("Потік %i зараз прокинувся.\n" % i)
for i in range(10):
th = Thread(target=sleep_me, args=(i,))
th.start()
Вивід буде приблизно таким:
Потік 0 засинає на 5 секунд.
Потік 3 засинає на 5 секунд.
Потік 1 засинає на 5 секунд.
Потік 4 засинає на 5 секунд.
Потік 2 засинає на 5 секунд.
Потік 5 засинає на 5 секунд.
Потік 6 засинає на 5 секунд.
Потік 7 засинає на 5 секунд.
Потік 8 засинає на 5 секунд.
Потік 9 засинає на 5 секунд.
Потік 0 зараз прокинувся.
Потік 3 зараз прокинувся.
Потік 1 зараз прокинувся.
Потік 4 зараз прокинувся.
Потік 2 зараз прокинувся.
Потік 5 зараз прокинувся.
Потік 6 зараз прокинувся.
Потік 7 зараз прокинувся.
Потік 8 зараз прокинувся.
Потік 9 зараз прокинувся.
Порядок може бути взагалі будь-яким, і ми цей порядок не контролюємо!
threading.active_count()
Ця функція повертає кількість потоків, що виконуються на поточний момент. Змінимо останню програму, щоб вона виглядала ось так:
import time
import threading
from threading import Thread
def sleep_me(i):
print("Потік %i засинає на 5 секунд." % i)
time.sleep(5)
print("Потік %i зараз прокинувся." % i)
for i in range(10):
th = Thread(target=sleep_me, args=(i,))
th.start()
print("Запущено потоків: %i." % threading.active_count())
Результат буде приблизно такий:
Потік 0 засинає на 5 секунд.
Запущено потоків: 2.
Потік 1 засинає на 5 секунд.
Запущено потоків: 3.
Потік 2 засинає на 5 секунд.
Запущено потоків: 4.
Потік 3 засинає на 5 секунд.
Запущено потоків: 5.
Потік 4 засинає на 5 секунд.
Запущено потоків: 6.
Потік 5 засинає на 5 секунд.
Запущено потоків: 7.
Потік 6 засинає на 5 секунд.
Запущено потоків: 8.
Потік 7 засинає на 5 секунд.
Запущено потоків: 9.
Потік 8 засинає на 5 секунд.
Запущено потоків: 10.
Потік 9 засинає на 5 секунд.
Запущено потоків: 11.
Потік 0 зараз прокинувся.
Потік 5 зараз прокинувся.
Потік 2 зараз прокинувся.
Потік 9 зараз прокинувся.
Потік 3 зараз прокинувся.
Потік 7 зараз прокинувся.
Потік 1 зараз прокинувся.
Потік 8 зараз прокинувся.
Потік 6 зараз прокинувся.
Потік 4 зараз прокинувся.
Також зверніть увагу, що після запуску всіх потоків лічильник показує число 11, а не 10. Причина в тому, що основний потік також враховується нарівні з 10 іншими.
Синхронізація потоків
Є низка проблем, що виникають під час використання багатопоточності - спроба безлічі потоків отримати доступ до одного і того самого фрагмента даних може призвести до проблем несумісності або отримання спотвореної інформації (наприклад, фраза HWeol,rldo замість Hello, World на консолі). Подібні проблеми виникають, коли комп’ютеру не вказано спосіб організації потоків.
Як правильно наказати комп’ютеру синхронізувати потоки?
Для цього використовуються примітиви синхронізації - прості програмні механізми, що забезпечують гармонійну взаємодію потоків один з одним.
У цьому пості представлено деякі популярні примітиви синхронізації в Python, визначені в стандартному модулі threading.py.
Вивчимо Locks, RLocks, Semaphores, Events, Conditions і Barriers. Зрозуміло, можна створювати власні примітиви користувацької синхронізації. Почнемо з Locks як з найпростішого з примітивів і поступово перейдемо до більш складним.
Lock

Примітив Lock - найпростіший примітив у Python. Для Lock можливі тільки два стани - заблокований і розблокований.
Примітив створюється в розблокованому стані та містить два методи - acquire() і release(). Метод acquire() блокує Lock і виконання блоку доти, доки метод release() з іншої співпрограми не розблокує його. Потім він знову блокує Lock і повертає значення True. Метод release() викликається тільки в заблокованому стані - встановлює стан розблокування і негайно повертає керування. Виклик release() у розблокованому стані призводить до RunTimeError.
from threading import Lock, Thread
lock = Lock()
def add_one(li):
lock.acquire()
try:
li.append(1)
finally:
lock.release()
def add_two(li):
lock.acquire()
try:
li.append(2)
finally:
lock.release()
# те ж саме, що і конструкція:
# with lock:
# li.append(2)
threads = []
list_to_append = []
for func in [add_one, add_two]:
threads.append(Thread(target=func, args=(list_to_append,)))
threads[-1].start()
for thread in threads:
"""
Очікує завершення потоків перед тим, як перейти до основного скрипта.
"""
thread.join()
print(list_to_append)
Якщо не використовувати Lock, то ми не можемо бути впевнені, що наприкінці вийде [1, 2], могло б вийти і [2, 1].
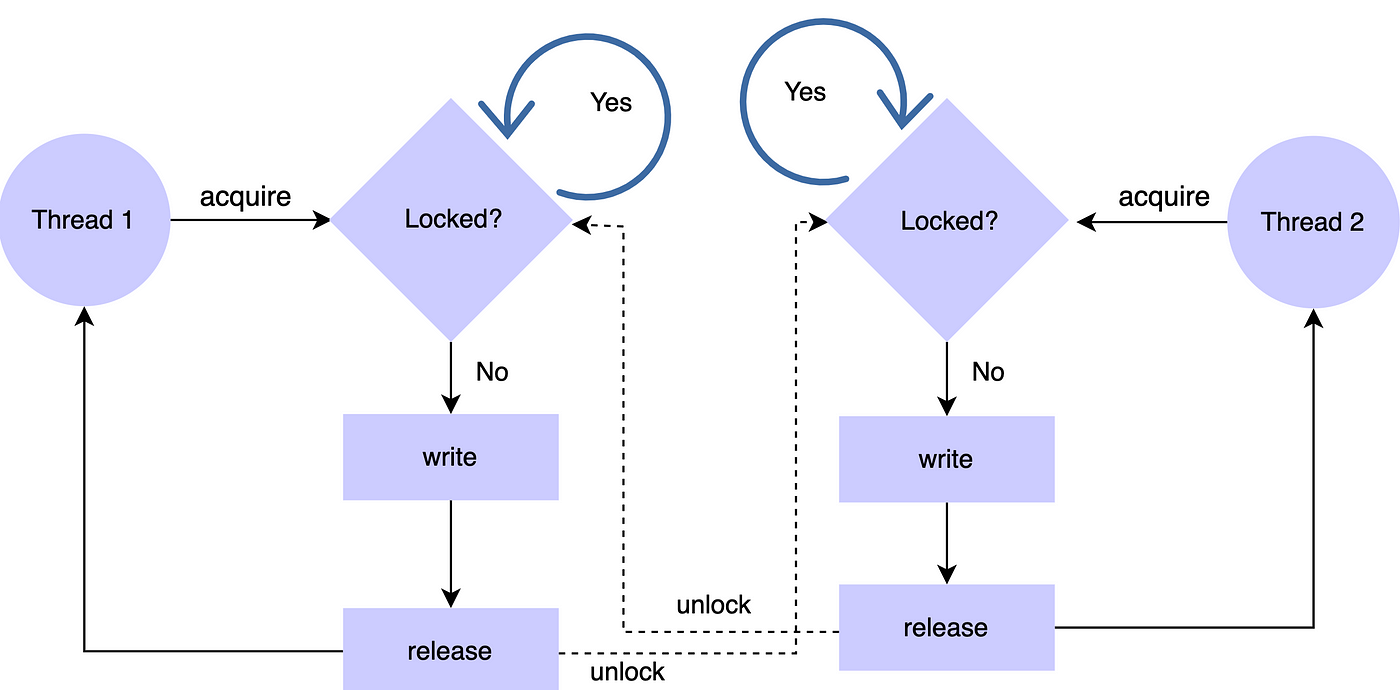
RLocks
Стандартний Lock не знає, який потік блокується в даний момент. Якщо блокування зберігається, блокується будь-який із потоків, які намагаються отримати доступ, навіть якщо це той самий потік, який вже утримує блокування. Саме для таких випадків і використовується RLock - блокування повторного входу. Ви можете розширити код у наступному фрагменті, додавши вихідні інструкції для демонстрації можливостей RLock запобігати небажаному блокуванню.
import threading
num = 0
lock = threading.Lock()
lock.acquire()
num += 1
#lock.acquire() # Це заблокує.
num += 2
lock.release()
print(num)
# З RLock такої проблеми не виникає.
lock = threading.RLock()
lock.acquire()
num += 3
lock.acquire() # Це не заблокує.
num += 4
lock.release()
lock.release() # Потрібно один раз викликати release для кожного виклику acquisition.
print(num)
Можливе рекурсивне використання RLock - коли батьківський виклик функції блокує вкладений виклик. Таким чином, RLock використовуються для вкладеного доступу до загальних ресурсів.
Semaphore
Семафори - це просто додаткові лічильники. Виклик acquire() буде блокуватися семафором тільки після перевищення певної кількості запущених потоків acquire(). Значення відповідного лічильника зменшується на кожен виклик acquire() і збільшується на кожен виклик release(). Значення ValueError виникатиме, якщо виклики release() намагатимуться збільшувати значення лічильника після досягнення заданого максимального значення (кількості потоків, які допустимі семафором acquire() до застосування блокування). Наступний код демонструє використання семафорів для простого завдання виробник-споживач.

from threading import Thread, BoundedSemaphore
from time import sleep, time
ticket_office = BoundedSemaphore(value=3)
def ticket_buyer(number):
start_service = time()
with ticket_office:
sleep(1)
print(f"client {number}, service time: {time() - start_service}")
buyer = [Thread(target=ticket_buyer, args=(i,)) for i in range(5)]
for b in buyer:
b.start()
Приблизний вивід:
client 0, service time: 1.005223274230957
client 1, service time: 1.0052969455718994
client 2, service time: 1.0055789947509766
client 4, service time: 2.010823965072632
client 3, service time: 2.0109810829162598
Щойно перші потоки звільнилися, роботу розпочали наступні.
Event (Подія)

Події за своїм призначенням і алгоритмом роботи схожі на розглянуті раніше умовні змінні. Основне завдання, яку вони вирішують - це взаємодія між потоками через механізм оповіщення. Об’єкт класу Event керує внутрішнім прапором, який скидається за допомогою методу clear() і встановлюється методом set(). Потоки, які використовують об’єкт Event для синхронізації блокуються під час виклику методу wait(), якщо прапор скинуто.
Методи класу Event:
-
is_set()повертає True, якщо прапор перебуває у зведеному стані. -
set()переводить прапор у зведений стан. -
clear()переводить прапор у скинутий стан. -
wait(timeout=None)блокує потік, який викликав цей метод, якщо прапор відповідного Event-об’єкта перебуває в скинутому стані. Час перебування в стані блокування можна задати через параметрtimeout.
from threading import Thread, Event
event = Event()
def worker(name: str):
event.wait() # чекаємо, поки прапор не зміниться
print(f"Worker: {name}")
# Clear event
event.clear()
# Create and start workers
workers = [Thread(target=worker, args=(f"wrk {i}",)) for i in range(5)]
for w in workers:
w.start()
print("Main thread")
event.set() # Зводимо прапор, чим і запускаємо функції зверху
Main thread
Worker: wrk 1
Worker: wrk 2
Worker: wrk 3
Worker: wrk 4
Worker: wrk 0
Їхній порядок ми не контролюємо, тільки подію, за якою вони спрацьовують.
Conditions
Продвинуті івенти.
Під час створення об’єкта Condition ви можете передати в конструктор об’єкт Lock або RLock, з яким хочете працювати.
Перелічимо методи об’єкта Condition з коротким описом:
-
acquire(*args)- захоплення об’єкта-блокування. -
release()- звільнення об’єкта-блокування. -
wait(timeout=None)- блокування виконання потоку до оповіщення про зняття блокування. Через параметрtimeoutможна задати час очікування сповіщення про зняття блокування. Якщо викликатиwait()на умовній змінній, у якої попередньо не було викликаноacquire(), то буде викинуто винятокRuntimeError. -
notify(n=1)знімає блокування із зупиненого методомwait()потоку. Якщо необхідно розблокувати кілька потоків, то для цього слід передати їхню кількість через аргументn. -
notify_all()знімає блокування з усіх зупинених методомwait()потоків.
from threading import Thread, Condition
condition = Condition()
def worker_wait(name: str):
condition.acquire()
print(f"Worker: {name} after ac")
condition.wait()
print(f"Worker: {name} after w")
condition.release()
def worker_notify(name: str):
condition.acquire()
print(f"Worker: {name} after ac")
condition.notify()
print(f"Worker: {name} after n")
condition.release()
# Create and start workers
workers_wait = [Thread(target=worker_wait, args=(f"wrk {i}",)) for i in range(5)]
workers_notify = [Thread(target=worker_notify, args=(f"wrk {i + 5}",)) for i in range(5)]
for w in workers_wait:
w.start()
for w in workers_notify:
w.start()
Результат:
Worker: wrk 0 after ac
Worker: wrk 1 after ac
Worker: wrk 2 after ac
Worker: wrk 3 after ac
Worker: wrk 4 after ac
Worker: wrk 5 after ac
Worker: wrk 5 after n
Worker: wrk 0 after w
Worker: wrk 6 after ac
Worker: wrk 6 after n
Worker: wrk 1 after w
Worker: wrk 7 after ac
Worker: wrk 7 after n
Worker: wrk 8 after ac
Worker: wrk 8 after n
Worker: wrk 2 after w
Worker: wrk 9 after ac
Worker: wrk 9 after n
Worker: wrk 3 after w
Worker: wrk 4 after w
Process finished with exit code 0
Перші 5 запускаються і зупиняються на команді wait(). 6-ий (з номером 5) теж блокується і викликає notify(), чим і “відпускає” потік з номером 0.
Timer
Модуль threading надає зручний інструмент для запуску завдань за таймером - клас Timer. Під час створення таймера вказується функція, яка буде виконана, коли він спрацює. Timer реалізований як потік, що є спадкоємцем від Thread, тому для його запуску необхідно викликати start(), якщо необхідно зупинити роботу таймера, то викличте cancel().
Конструктор класу Timer:
Timer(interval, function, args=None, kwargs=None)
Параметри:
-
interval- кількість секунд, після закінчення яких буде викликана функціяfunction. -
function- функція, виклик якої потрібно здійснити за таймером. -
args,kwargs- аргументи функціїfunction.
Методи класу Timer:
cancel()зупиняє виконання таймера.
from threading import Timer
timer = Timer(interval=3, function=lambda: print("Message from Timer!"))
timer.start()
Програма піде далі, а функція буде виконана через 3 секунди.
Ще буває Barrier (бар’єр). Він дає змогу реалізувати алгоритм, коли необхідно дочекатися завершення роботи групи потоків, перш ніж продовжити виконання завдання.
GIL. Global Interpreter Lock

Python Global Interpreter Lock (GIL) (Блокування глобального інтерпретатора ) - це своєрідне блокування, що дає змогу тільки одному потоку керувати інтерпретатором Python. Це означає, що в будь-який момент часу буде виконуватися тільки один конкретний потік.
Робота GIL може здаватися несуттєвою для розробників, які створюють однопотокові програми. Але в багатопотокових програмах відсутність GIL може негативно позначатися на продуктивності процесоро-залежних програм.
Оскільки GIL дає змогу працювати лише одному потоку навіть у багатопотоковому додатку, він заробив репутацію “сумнозвісного відомої” функції.
Фактично Python не викликає багато потоків одночасно, а тільки дуже швидко їх перемикає, що робить все багатопотокові обчислення за фактом однопотоковими.

Що за проблему в Python вирішує GIL?
Python підраховує кількість посилань для коректного керування пам’яттю. Це означає, що створені в Python об’єкти мають змінну підрахунку посилань, у якій зберігається кількість усіх посилань на цей об’єкт. Як тільки ця змінна тає рівною нулю, пам’ять, виділена під цей об’єкт, звільняється.
Ось невеликий приклад коду, що демонструє роботу змінних підрахунку посилань:
import sys
a = []
b = a
sys.getrefcount(a)
3
У цьому прикладі кількість посилань на порожній масив дорівнює 3. На цей масив посилаються: змінна a, змінна b і аргумент, переданий функції sys.getrefcount().
Проблема, яку розв’язує GIL, пов’язана з тим, що в багатопотоковому додатку одразу кілька потоків можуть збільшувати або зменшувати значення цього лічильника посилань. Це може призвести до того, що пам’ять очиститься неправильно і видалиться той об’єкт, на який ще існує посилання.
Лічильник посилань можна захистити, додавши блокіратори на всі структури даних, які розповсюджуються за кількома потокам. У такому разі лічильник буде змінюватися виключно послідовно.
Але додавання блокування до кількох об’єктів може призвести до появи іншої проблеми - взаємоблокування (англ. deadlocks), яка виходить тільки якщо блокування є більш ніж на одному об’єкті. До того ж ця проблема теж знижувала б продуктивність через багаторазове встановлення блокіраторів.
GIL - це одиночний блокіратор самого інтерпретатора Python. Він додає правило: будь-яке виконання байт-коду в Python вимагає блокування інтерпретатора. У такому разі можна виключити взаємоблокування, оскільки GIL буде єдиною блокуванням у додатку. До того ж його вплив на продуктивність процесора зовсім не критичний. Однак варто пам’ятати, що GIL впевнено робить будь-яку програму однопотоковою.
Незважаючи на те, що GIL використовується і в інших інтерпретаторах, наприклад у Ruby, він не є єдиним рішенням цієї проблеми. Деякі мови вирішують проблему потокобезпечного звільнення пам’яті за допомогою збирання сміття.
Як упоратися з GIL?
Якщо GIL у вас викликає проблеми, ось кілька рішень, які ви можете спробувати:
-
Багатопроцесорність проти багатопоточності.
Досить популярне рішення, оскільки у кожного Python-процесу є власний інтерпретатор із виділеною під нього пам’яттю, тому з GIL проблем не буде. -
Корутини. Про них на наступному занятті.
CPU-bound та IO-Bound операції
Ще один важливий момент, з погляду розробника – різниця між CPU-bound та IO-bound операціями. CPU-Bound операції навантажують обчислювальні потужності поточного пристрою, а IO-Bound дозволяють виконати завдання поза поточною залізницею.

Різниця важлива тим, що кількість одночасних операцій залежить від того, до якої категорії вони належать. Цілком нормально запустити паралельно сотні IO-Bound операцій і сподіватися, що вистачить ресурсів обробити всі результати. Запускати паралельно занадто велике число CPU-bound операцій (більше, ніж число обчислювальних пристроїв) безглуздо.
Multiprocessing (Багатопроцесорність)

Що таке багатопроцесорна обробка Python?
Спочатку поговоримо про паралельну обробку. Це спосіб одночасно розбивати та запускати програмні завдання на декількох мікропроцесорах. По суті, це спроба скоротити час обробки і це те, чого ми можемо досягти за допомогою комп’ютера з двома або більше процесорами, або з використанням комп’ютерної мережі. Ми також називаємо це паралельними обчисленнями.
Python Multiprocessing

Отже, тепер перейдемо до Python Multiprocessing, це спосіб підвищити продуктивність шляхом створення паралельного коду. Виробники процесорів роблять це можливим, додаючи більше ядер до своїх процесорів. У багатопроцесорній системі додатки розбиваються на більш дрібні підпрограми для самостійної роботи. Погляньте на однопроцесорну систему. Враховуючи кілька процесів одночасно, він намагається переривати і перемикатися між завданнями. Як би ви себе відчували, будучи єдиним шеф-кухарем на кухні з сотнями клієнтів? Ви мали б виконувати всі звичайні завдання від випічки до замісу тіста.
Коли це корисно?
-
Мультипроцесор - комп’ютер із кількома центральними процесорами.
-
Багатоядерний процесор - один обчислювальний компонент із більш ніж однією незалежною фактичною одиницею обробки/ядрами.
У будь-якому разі процесор може виконувати кілька завдань одночасно, призначаючи процесор для кожного завдання.
Приклад:
from multiprocessing import Process
def square(n):
print("Число в квадраті", n ** 2)
def cube(n):
print("Число в кубі", n ** 3)
if __name__ == "__main__":
p1 = Process(target=square, args=(7,))
p2 = Process(target=cube, args=(7,))
p1.start()
p2.start()
p1.join()
p2.join()
print("Кінець")
Відмінність від багатопоточності в тому, що в цьому випадку кожен окремий процес буде виконуватися окремим ядром або процесором, і ніяк не блокується GIL.
Але процедура створення нового процесу досить дорога, і немає жодного сенсу створювати новий процес для простих дій.
У кожного процесу є id, назва і т. д. Ці дані завжди можна витягти.
Блокування процесів
Так само як і з потоками у нас може бути ситуація, коли різні процеси обробляють одні й ті самі дані, і щоб бути впевненим, що дії не відбуваються одночасно, ми можемо заблокувати процес, синтаксис ідентичний.
from multiprocessing import Process, Lock
lock = Lock()
def printer(item):
lock.acquire()
try:
print(item)
finally:
lock.release()
if __name__ == "__main__":
items = ['nacho', 'salsa', 7]
for item in items:
p = Process(target=printer, args=(item,))
p.start()
Для багатопроцесорності працюють рівно ті ж самі блокування, як і для багатопоточності.
Pool (Пул викликів)
Пул - це можливість створити відразу необхідну кількість процесів, а не робити це по одному. У цьому прикладі ми відразу створюємо 3 процеси для трьох паралельних обчислень.
from multiprocessing import Pool
def double(n):
return n * 2
if __name__ == '__main__':
nums = [2, 3, 6]
pool = Pool(processes=3)
print(pool.map(double, nums))
Якщо нам необхідно обчислювати одну дію на трьох процесорах, нам допоможе функція apply_async():
from multiprocessing import Pool
def double(n):
return n * 2
if __name__ == '__main__':
pool = Pool(processes=3)
result = pool.apply_async(double, (7,))
print(result.get())
Домашнє завдання:
- Написати функцію, яка робитиме запити (через requests) на
https://google.com,https://amazon.com,https://microsoft.com. Синхронно (звичайним способом), багатопоточно, багатопроцесорно, порівняти час виконання, зробити висновки.
- 1.1 зробити по 5 запитів на кожен сайт, отримати час.
-
Написати функцію, яка зводить числа 2, 3 і 5 у 1000000 ступінь. Синхронно (звичайним способом), багатопоточно, багатопроцесорно, порівняти час виконання, зробити висновки.
(спочатку перевіряємо на ступені 1000) -
Відповісти, який спосіб для яких завдань годиться краще, і чому.