#47. Deployment
Deployment. Media files, static files. AWS. Gunicorn та nginx.

Static і Media файли

Static файли - файли, які не є частиною обов’язкових файлів для роботи системи ( *.py, *.html), але необхідні для зміни відображення (*.css, *.js, *.jpg). До таких файлів є доступ із коду, і зазвичай вони не можуть бути змінені з боку користувача (шрифти на сайті, css стилі, картинка на фоні тощо)
Media файли - файли, завантажені користувачами (незалежно від привілеїв), наприклад, аватарки, картинки товарів, голосові повідомлення. До таких файлів у репозиторії немає і не повинно бути доступу.
Де їх зберігати?
Static файли практично завжди розкидані по додатках проекту, що дуже зручно під час розробки, але при використанні їх набагато простіше зберігати в одному місці, і теж поза проектом. Media файли потрібно зберігати окремо від статики, інакше можна отримати велику кількість проблем. Найпростіше створити дві окремі папки static і media або одну папку files, а в ній уже вкладені папки static і media.
Як це налаштовується в Django?
У рамках Django при створенні проекту в початковій версії setting.py в INSTALLED_APPS автоматично додається django.contrib.staticfiles, саме цей додаток відповідає за те, як будуть оброблятися статичні файли.
# settings.py
STATIC_URL = "static/"
Зазначений параметр STATIC_URL буде перетворено на URL, за яким можна отримати статичні файли.
Наприклад, "/static/" або "http://static.example.com/"
У першому випадку під час запиту до статики буде виконано запит на поточний URL з приставкою http://127.0.0.1:8000/static/.
У другому запити будуть зроблені на окремий URL.
Змінна DEBUG
У settings.py є змінна DEBUG, за дефолтом вона дорівнює True, але за що вона відповідає?
Здебільшого вона відповідає за те, як поводитися в разі помилок (найчастіше 500-х). Якщо ви робите неправильний запит (не туди, не ті дані тощо), то ви бачите докладний опис того, чому ваш запит не вдався, на якому рядку коду впав, або немає такого URL, але ось такі є. Усе це відображається тільки тому, що змінна DEBUG=True.
Запущений сайт ніколи не покаже вам цю інформацію.
Змінна DEBUG і runserver
Насправді, якщо у вас DEBUG=True і ви запускаєте команду runserver, то запускається ще і django.contrib.staticfiles.views.serve(), який дає змогу відображати статичні файли в процесі розробки. При при завантаженні проекту в реальне використання змінну DEBUG потрібно встановити в False і обробляти статичні файли зовнішніми засобами, поговоримо про них нижче.
STATICFILES_DIRS
Список папок, у яких зберігається ваша статика для розробки, найчастіше це папки static у різних додатках, наприклад, authenticate/static, billing/static , тощо.
НЕ ПОВИНЕН МІСТИТИ ЗНАЧЕННЯ ЗІ ЗМІННОЇ STATIC_ROOT!!!
Наступний шлях дозволить покласти статику у корінь проекту, аналогічно templates.
STATICFILES_DIRS = [BASE_DIR / "static"]
STATIC_ROOT
Змінна, що містить шлях до папки, в яку всю знайдену статику з папок у змінній STATICFILES_DIRS збере команда
python manage.py collectstatic
Як це працює на практиці? Під час розробки використовуються статичні файли з папок різних додатків, а для продакшена налаштовується скрипт, який при будь-якій зміні буде запускати команду collectstatic, яка буде збирати всю статику в те місце, яке вже обробляється сторонніми сервісами, про які нижче.
Як користуватися?
У шаблоні, де ми можемо використовувати template tag static:
{% load static %}
<img src="{% static 'my_app/img/example.jpg' %}" alt="example">
<script src="{% static 'myapp/js/alert.js' %}"></script>
<link rel="stylesheet" href="{% static 'myapp/css/base.css' %}">
MEDIA_URL
За аналогією зі статикою таке ж налаштування для медіа.
# settings.py
MEDIA_URL = '/media/'
MEDIA_ROOT = BASE_DIR / "media"
MEDIA_ROOT
Абсолютний шлях до папки, в якій ми зберігатимемо користувацькі файли.
Медіа збирати не потрібно, оскільки ми не можемо її змінювати, це тільки користувацький привілей.
Deployment (Розгортання)
Deployment - це розгортання вашого проєкту для використання його з інтернету, а не локально.
Що для цього необхідно? Потрібен сервер (насправді ним може бути будь-який пристрій: комп, телефон тощо), але у сервера є одна особливість, йому потрібно працювати завжди, ми ж не хочемо, щоб наш сайт або додаток переставав працювати.
Щоб організувати 100% uptime, найчастіше використовують хмарні сервери, багато компаній готові надати такі сервера на платній основі. Один із найнадійніші та найчастіше використовувані - це сервера компанії Amazon, також у Amazon дуже велика інфраструктура й екосистема для обслуговування сервером, але про це наступного разу.
Amazon Web Services (AWS)
Amazon Web Services або AWS (читається як ей дабл ю ес) є дочірньою компанією Amazon.com, що надає платформу хмарних обчислень в оренду приватним особам, компаніям та урядам на основі платної підписки. Існує і безкоштовна підписка, яка доступна протягом перших 12 місяців. Технологія дозволяє абонентам мати у своєму розпорядженні повноцінний віртуальний кластер комп’ютерів, який завжди доступний через Інтернет. Віртуальні комп’ютери AWS мають більшість атрибутів реального комп’ютера, включаючи апаратні пристрої (процесор, відеокарту, локальну та оперативну пам’ять, жорсткий диск або SSD-накопичувач); операційну систему на вибір; мережу; і попередньо встановлені прикладні програми, такі як вебсервер, база даних, CRM і т. д. Кожна система AWS також віртуалізує консольний ввід/вивід (клавіатура, дисплей і миша), що дозволяє користувачам AWS підключитися до своєї системи AWS за допомогою браузера. Браузер виступає як вікно у віртуальний комп’ютер, дозволяючи користувачу входити в систему, налаштовувати та використовувати свої віртуальні системи так само, як справжній, фізичний комп’ютер. Це дозволяє їм налаштувати систему так, щоб надавати інтернет-орієнтовані сервіси та послуги своїм клієнтам.

AWS надає доступ більш ніж до 70 сервісів, що охоплюють широкий спектр, включаючи обчислення та зберігання даних, їхню передачу по мережі, аналітику, мобільні застосунки, інструменти для розробників і т. д. Найпопулярніші з них є Amazon Elastic Compute Cloud (EC2) і Amazon Simple Storage Service (S3). Більшість служб не надаються безпосередньо кінцевим користувачам, але замість цього пропонуються функціональні можливості через API, які розробники можуть використовувати в своїх програмах.

Amazon EC2 (Elastic Compute Cloud)

Сервіс, який надає нам виділені потужності, називається EC2.
Для початку нам необхідний акаунт на платформі AWS.
Треба зареєструватися, також необхідний картка банку. Без валідних даних з картки може не пройти реєстрація акаунта.
Посилання на AWS

EC2 - це сервіс, який дає змогу запускати віртуальні сервери з різною потужністю на різних операційних системах.
Для нашого випадку ми розглядатимемо найслабший за характеристиками сервер (t2.nano) на базі Linux (Ubuntu Server LTS).
На наступній вкладці обираємо потужність сервера і пару ключів для підключення по SSH.



Загальна теорія щодо деплою Django
Для деплою Django застосунку використовується два різні сервери, перший - для запуску застосунку локально на сервері, другий - як проксі, щоб вихід в інтернет пов’язати з цим локально запущеним сервером і надати доступ до статики та медіа. За обробку даних відповідатиме перший сервер, за безпеку і розподіл навантажень - другий.
Перший сервер - це WSGI (Web-Server Gateway Interface), працює приблизно так:

Як WSGI-сервер може бути використана досить велика кількість різних серверів:
- uWSGI
- Bjoern
- uWSGI
- mod_wsgi
- Meinheld
- Gunicorn
І так далі, це далеко не повний список. Як приклад ми будемо використовувати Gunicorn (на моїй практиці самий використовуваний сервер).
Також існує технологія ASGI (Asynchronous Standard Gateway Interface) - це поліпшення технології WSGI, основні сервери для ASGI:
- Daphne
- Hypercorn
- Uvicorn
Теж часто використовувані технології, і, найімовірніше, далі використовуватимуться дедалі частіше.
Як проксі-сервер можуть бути використані:
- Nginx
- Apache
runserver
Може виникнути ідея, а чому б не використовувати команду runserver? Навіщо нам взагалі якісь додаткові сервера? Команда runserver не передбачає навіть відносно серйозних навантажень, навіть за умовних 100 користувачів базова команда буде захлинатися.
Приклад розгортання

Розглянемо, як розгорнути наш проєкт на прикладі EC2 (Ubuntu) + Gunicorn + Nginx
Для початку необхідно зайти на наш EC2 сервер за допомогою SSH.
Якщо ви використовуєте Windows, то найпростіший спосіб використовувати SSH - це або клієнт putty, або встановити Git CLI, git-інтерфейс підтримує командуssh.
Свіжостворений інстанс не містить взагалі нічого, навіть інтерпретатора Python, а отже, нам необхідно його встановити, але разом із ним встановимо й інші потрібні пакети (БД, сервери тощо).
sudo apt update
sudo apt install python3-pip python3-dev python3-venv libpq-dev postgresql postgresql-contrib nginx curl
База даних
Як створити базу даних і користувача з доступом до неї, ви вже знаєте, заходимо в консоль postgresql і робимо це:
sudo -u postgres psql
CREATE USER myuser WITH ENCRYPTED PASSWORD 'mypass';
CREATE DATABASE mydb;
GRANT ALL PRIVILEGES ON DATABASE mydb TO myuser;
Змінні операційної системи
Щоб вносити деякі параметри в код, використовуються змінні операційної системи, припустимо, у файлі settings.py ми можемо зберігати пароль від бази даних, ключі від сервісів і багато іншої інформації, яку не можна розголошувати, але в разі, якщо ви залишите ці дані в коді, вони потраплять на git, цього допускати не можна.
Для використання змінних в ОС Linux використовується команда
export var_name="value".
Якщо просто в консоль внести команду експорту, вона обнулиться після перезавантаження інстансу, нас це не влаштовує, тому експорт змінних потрібно вносити до файлу, що завантажується під час кожного запуску, наприклад, ~/.bashrc, відкриваємо
sudo nano ~/.bashrc
і в самому кінці дописуємо:
export PROD='True';
export DBNAME='mydb';
export DBUSER='myuser';
export DBPASS='mypass';
Не забуваємо виконати source, щоб застосувати ці зміни.
Для gunicorn простіше занести всі змінні в окремий файл, і ми будемо використовувати його надалі, створимо ще один файл із цими ж змінними.
sudo nano /home/ubuntu/.env
PROD='True'
DBNAME='mydb'
DBUSER='myuser'
DBPASS='mypass'
Правки в settings.py
Один зі зручних способів розділити налаштування на локальні та продакшен - це все ті ж змінні операційної системи, наприклад, додати в проєкт на рівні файлу settings.py ще два файли: settings_prod.py і settings_local.py, в основний файл потрібно імпортувати модуль os і в кінці дописати:
if os.environ.get('PROD'):
try:
from .settings_prod import *
except ImportError:
pass
else:
try:
from .settings_local import *
except ImportError:
pass
Таким чином ми зможемо розділити налаштування залежно від того, чи є в операційній системі змінна PROD.
У settings_prod.py вкажемо:
import os
DEBUG = False
ALLOWED_HOSTS = ['ip-address']
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': os.environ.get('DBNAME'),
'USER': os.environ.get('DBUSER'),
'PASSWORD': os.environ.get('DBPASS'),
'HOST': os.environ.get('DBHOST', '127.0.0.1'),
'PORT': os.environ.get('DBPORT', '5432'),
}
}
Параметр DEBUG = False , оскільки нам не потрібно відображати подробиці помилок.
У ALLOWED_HOSTS потрібно вказувати URL та/або IP, за яким буде доступний застосунок. Як вказати там URL, ми поговоримо на наступному занятті, а поки можна вказати там IP, який ми отримали в Amazon після створення інстансу:

git clone і віртуальне оточення
Клонуємо код нашого проєкту:
git clone https://github.com/your-git/your-repo.git
Створюємо віртуальне оточення
cd ~/
mkdir venv
python3 -m venv venv/
І активуємо його:
source ~/venv/bin/activate
Переходимо в розділ із проєктом і встановлюємо все, що є в requirements.txt:
cd ~/proj_name
pip install -r requirements.txt
Якщо локально ви не працювали з базою postgresql, то необхідно доставити модуль для роботи з ним:
pip install psycopg2-binary
Після чого ви маєте успішно застосувати міграції:
python manage.py migrate
Перевіряємо працездатність сервера
Для перевірки того, що ваш додаток можна розгортати, запустимо його через стандартну команду:
python manage.py runserver
Щоб це спрацювало, необхідно дозволити використовувати порт, який ми будемо використовувати для тесту, за стандартом це порт номер 8000:
sudo ufw allow 8000
Ми відкрили порт з боку сервера, але поки що він закритий з боку Amazon, давайте тимчасово відкриємо його теж. Для цього йдемо на сторінку Amazon з описом інстансу, відкриваємо вкладку Security і натискаємо на назву сек’юриті групи:
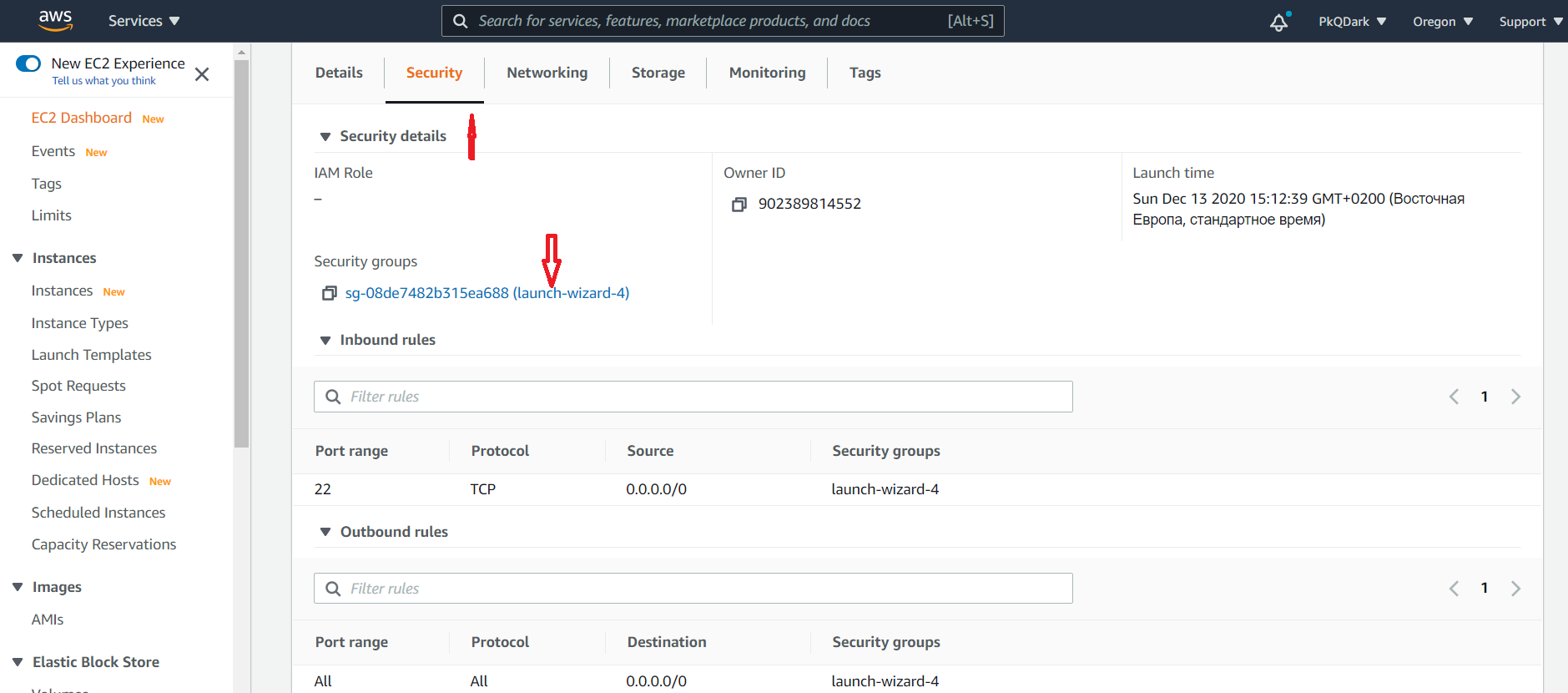
Клікаємо на Edit inbound rules.
Додаємо правило Custom TCP для порту 8000:
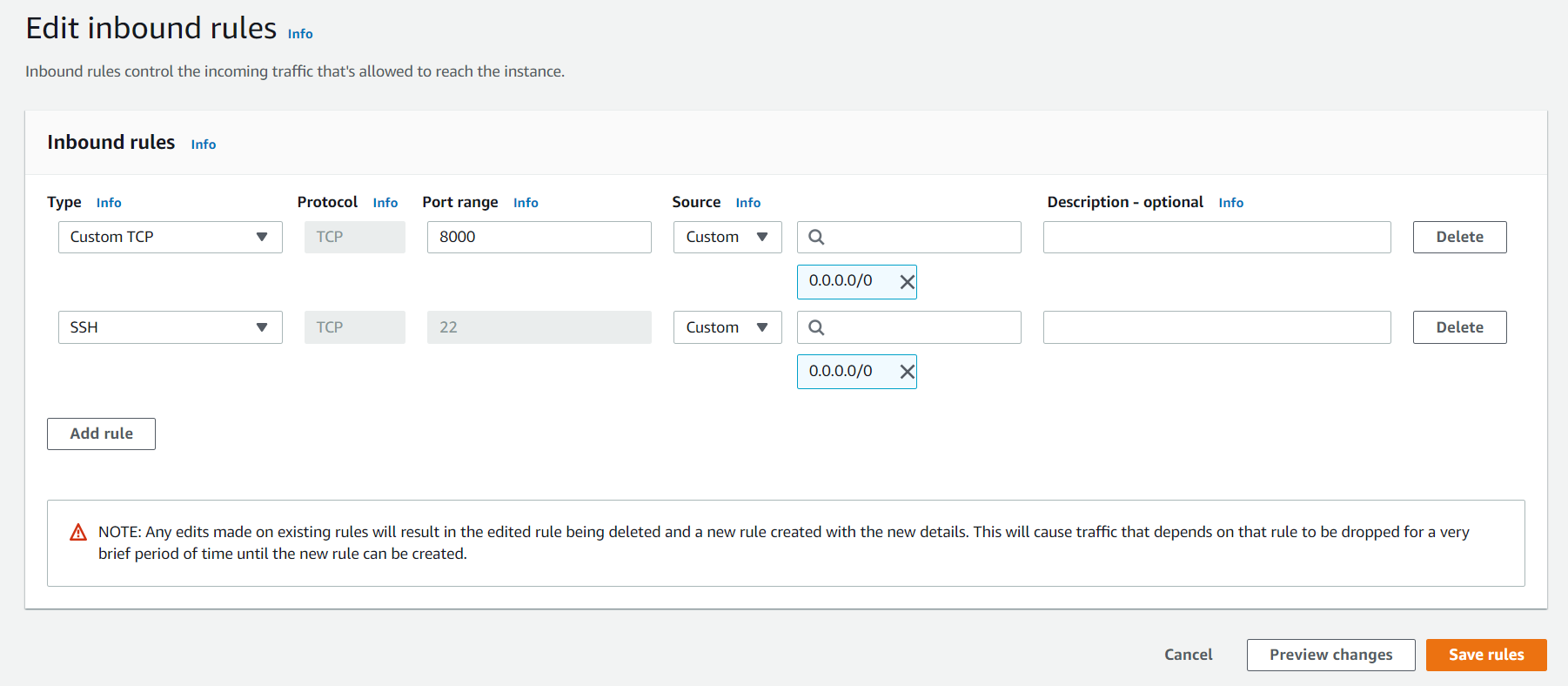
Після цього можна запустити команду runserver з такими правилами:
python manage.py runserver 0.0.0.0:8000
Якщо ви все зробили правильно, то тепер ви можете відкрити в браузері IP-адресу, яку вам видав Amazon, з портом 8000:
# Наприклад
http://54.186.155.252:8000/
Зверніть увагу, сайт відкриється БЕЗ СТАТИКИ, тому що runserver при DEBUG = False не повинен обробляти статику.
Перевіряємо gunicorn
Встановлюємо gunicorn
pip install gunicorn
Як ви пам’ятаєте, gunicorn - це WSGI сервер. Якщо ви відкриєте папку з settings.py, то ви побачите там ще два файлу wsgi.py і asgi.py.
Вони потрібні для того, щоб запускати сервери в “бойовому” режимі.
Для перевірки роботи gunicorn запустимо сервер через нього:
gunicorn --bind 0.0.0.0: 8000 Proj.wsgi
Де Proj - це назва папки, в якій лежить файл wsgi.py.
Знову ж таки, якщо ви все зробили правильно, то той самий URL все ще працюватиме.
# Наприклад
http://54.186.155.252:8000/
Поняття сокет-файлу
У Linux абсолютно все - це файл. Розгорнутий сервер - це теж файл. Так ось, якщо ми використовуємо два сервери, і один слухає другий, то давайте розгортати перший теж як файл. Такий файл називатиметься сокет-файлом.
Демонізація gunicorn
Запускати сервер руками дуже захоплююче, але не дуже ефективно, давайте демонізуємо gunicorn для запуску сервера в сокет-файл, і зробимо так, щоб цей сервер запускався відразу під час запуску системи, щоб навіть якщо ми перезавантажимо інстанс, сервер все одно працював.
Скористаємося вбудованою в Linux системою systemd (системна демонізація).
Створимо системний файл для опису сокета:
sudo nano /etc/systemd/system/gunicorn.socket
#/etc/systemd/system/gunicorn.socket
[Unit]
Description=gunicorn socket
[Socket]
ListenStream=/home/ubuntu/proj/run/gunicorn.sock
[Install]
WantedBy=sockets.target
Блок Unit відповідає за опис демона.
Блок Socket відповідає за те, де буде знаходитися файл сокета, proj у цьому випадку - назва папки з проектом,
run - назва папки з файлом сокета (так чомусь прийнято називати).
Блок Install відповідає за автоматичний запуск під час запуску системи.
Збережіть файл і закрийте його.
Тепер потрібно створити файл сервісу, який і буде виконувати запуск:
```sudo nano /etc/systemd/system/gunicorn.service``
Назви сервісу і сокета мають збігатися:
[Unit]
Description=gunicorn daemon
Requires=gunicorn.socket
After=network.target
[Service]
User=ubuntu
Group=www-data
WorkingDirectory=/home/ubuntu/myprojectdir
EnvironmentFile=/home/ubuntu/.env
ExecStart=/home/ubuntu/venv/bin/gunicorn \
--access-logfile - \
--workers 3 \
--bind unix:/home/ubuntu/myprojectdir/run/gunicorn.sock \
myproject.wsgi:application
[Install]
WantedBy=multi-user.target
Блок Unit:
-
Description- опис. -
Requires- пов’язує сервіс із сокетом. -
After- відповідає за те, щоб запускати модуль тільки після того, як буде доступ в інтернет.
Блок Service:
-
User- користувач, який має запускати скрипт, якщо ми використовуємо стандартного юзера, то це будеubuntu. -
Group- група безпеки, за дефолтом - цеwww-data. -
WorkingDirectory- папка, з якої буде запускатися скрипт, у нашому випадку це папка з проектом, де лежитьmanage.py. -
EnvironmentFile- файл зі змінними. -
ExecStart- сам скрипт, нам потрібно запустити gunicorn з віртуального оточення, але ми не можемо запустити спочаткуsource, але при створенні віртуального оточення, ми всього лише складаємо всі скрипти в іншу папку.
/home/ubuntu/venv/bin/gunicorn - це фізичне розташування скрипта
--access-logfile - --workers 3 --bind unix:/home/ubuntu/myprojectdir/run/gunicorn.sock myproject.wsgi:application
Це налаштування самого скрипта, log level - це місце для запису логів, worker - їхня кількість, bind - місце, куди скласти файл (unix: означає, що буде файл), myproject - назва папки, де лежить wsgi.py
Блок Install відповідає за автоматичний запуск під час запуску системи для будь-якого користувача.
Зберігаємо файл і закриваємо
Для запуску сокета потрібно запустити його із системи:
sudo systemctl start gunicorn.socket
sudo systemctl enable gunicorn.socket
Наступного разу цього робити не потрібно, все запуститься автоматично.
Перевіримо запуск сокета
sudo systemctl status gunicorn.socket
Якщо тут ми не бачимо жодних помилок, то потрібно перевірити наявність файлу сокета. Якщо все є, то створення сокета працює.
Перевіримо його активацію:
sudo systemctl status gunicorn
Повинні побачити приблизно такий статус:
gunicorn.service - gunicorn daemon
Loaded: loaded (/etc/systemd/system/gunicorn.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Спробуємо виконати запит до нашого сокета:
curl --unix-socket /home/ubuntu/proj/run/gunicorn.sock localhost
І перевіримо статус ще раз, тепер він буде active.
Рестарт gunicorn
Тепер ми можемо перезапускати наш сокет за 1 команду:
sudo systemctl restart gunicorn
Nginx
Nginx - це веб сервер, гнучкий і потужний веб-сервер.
Для перевірки роботи Nginx давайте налаштуємо базовий доступ до Nginx для нашої IP адреси, і не забуваємо додати 80 порт у сек’юриті групи Amazon.
Налаштуємо Nginx, якщо ви встановили Nginx (ми зробили це першою дією на цьому інстансі), то у вас буде існуватиме папка з базовими налаштуваннями Nginx, давайте створимо нове налаштування:
```sudo nano /etc/nginx/sites-available/myproject``
Де myproject - це назва вашого проєкту.
server {
listen 80;
server_name 54.186.155.252;
}
Зберегти і закрити, прокинути сімлінк у сусідню папку, яку за дефолтом обслуговує Nginx:
sudo ln -s /etc/nginx/sites-available/myproject /etc/nginx/sites-enabled/
ОБОВ’ЯЗКОВО! Додати 80 порт у security groups, дозволені на Amazon!!!
Якщо ви все зробили правильно, то за вашою IP-адресою без зазначення порту буде відкрито базову сторінку Nginx:
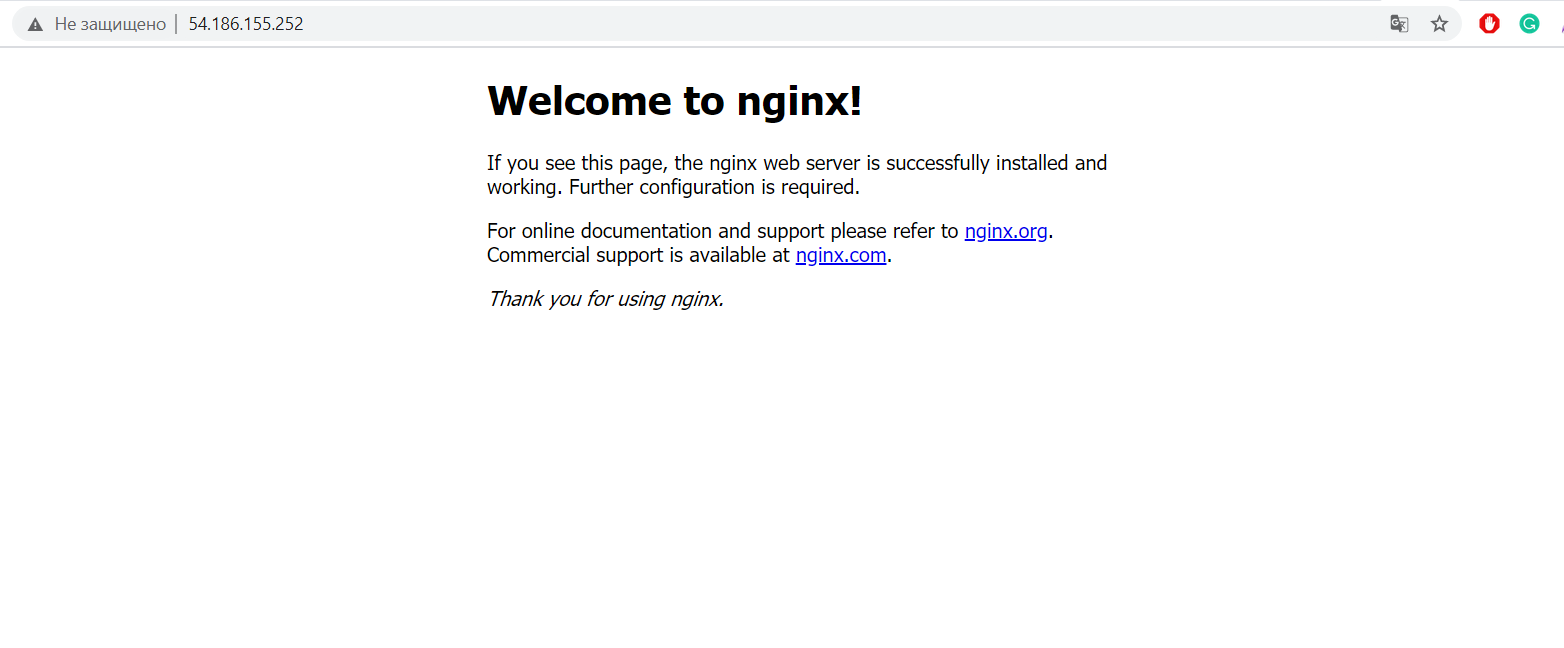
Щоб Nginx почав проксірувати наш проєкт, потрібно його вказати:
```sudo nano /etc/nginx/sites-available/myproject``
server {
listen 80;
server_name some_IP_or_url;
location / {
include proxy_params;
proxy_pass http://unix:/home/ubuntu/path/to/my/socket/gunicorn.sock;
}
}
Перезапускаємо Nginx і перевіряємо:
sudo systemctl restart nginx
Усе має працювати, але без статики.
Згадаймо самий початок лекції, що ми можемо придумати куди команда collectstatic має скласти статику. Запускаємо команду і вказуємо Nginx, що потрібно обробляти статику і медіа.
server {
listen 80;
server_name 34.221.249.152;
location /static/ {
root /home/ubuntu/deployment;
}
location /media/ {
root /home/ubuntu/deployment;
}
location / {
include proxy_params;
proxy_pass http://unix:/home/ubuntu/path/to/my/socket/gunicorn.sock;
}
}
Перезапускаємо Nginx і насолоджуємося результатом!
Не забуваємо закрити 8000 порт і на інстансі, і на Amazon у сек’юріті групі!!!
sudo ufw delete allow 8000
Сервіси Amazon
Amazon - це не тільки інстанси, це величезна, ні ВЕЛИЧЕЗНА екосистема з дуже великої кількості різних сервісів, які ми можемо використовувати для своїх потреб, там є майже все :) навіть генератори нейромереж.
Нас на цьому етапі цікавить кілька сервісів:
- RDS (Relational Database Service) - сервіс з використання SQL баз даних, що знаходитимуться на Amazon.
Навіщо це потрібно? По-перше, це надійно. Ми впевнені, що БД перебуває в хмарі, ми за неї платимо і Amazon гарантує її збереження. У разі зберігання БД на інстансі, БД у разі чого видалиться разом з інстансом. По-друге, у разі мікросервісної архітектури мікросервіси фізично можуть перебувати на абсолютно різних машинах, а потрібно використовувати одну й ту саму БД. Хмарна БД - найкращий для цього вибір. По-третє, під час використання Amazon RDS не не потрібно налаштовувати систему резервних копій, вона вже надана екосистемою Amazon у кілька кліків.
-
S3 Bucket - це просто сховище для файлів. Використовується для адекватного зберігання статики та медіа. Переваги дуже схожі на RDS. По-перше, ми не втратимо дані статики і медіа в разі “переїзду” на новий сервер. По-друге користувацькі медіа можуть займати величезні обсяги даних (наприклад, відеофайли). У разі зберігання їх на виділеному сервері ми впираємося в розмір сервера (що більше, то дорожче), а розширювати сервер тільки для “картинок і відео” не дуже розумно. Вартість S3 Bucket набагато менша і зручніша для цих цілей. По-третє, безпека, коли ви складаєте статику і медіа у себе, доступ до них є у всіх користувачів. Хто завгодно може відкрити наш JS почитати, це не дуже безпечно, раптом у нас там дірки. :) З медіа все ще гірше, це дані користувача, а ми виставляємо їх на загальний огляд. Це не дуже правильно. При використанні S3 Bucket ми можемо налаштувати безпеку, створити користувача в сервісі IAM (про неї далі). Django з коробки вміє додавати безпечний токен під час використання Amazon.
-
IAM - сервіс для налаштувань безпеки. Все насправді просто, там можна створити юзерів і групи юзерів, і роздати їм права на будь-які сервіси Amazon. Припустимо, одна група може тільки налаштовувати RDS і дивитися на EC2, а інша має повні права. У нашому випадку ми будемо створювати користувача з правами на читання S3 Bucket і використовувати його credentials для статики та медіа.
-
Route 53 - сервіс для налаштування DNS і реєстрації доменів, будемо використовувати його для того, щоб купити домен і перетворити наш IP на нормальний URL.
RDS
Ми будемо використовувати PostgreSQL.
Під час створення БД вам буде запропоновано створити майстер пароль для користувача postgres, його треба запам’ятати :)
Після створення бази даних потрібно відкрити подробиці та розділ Connectivity & security:
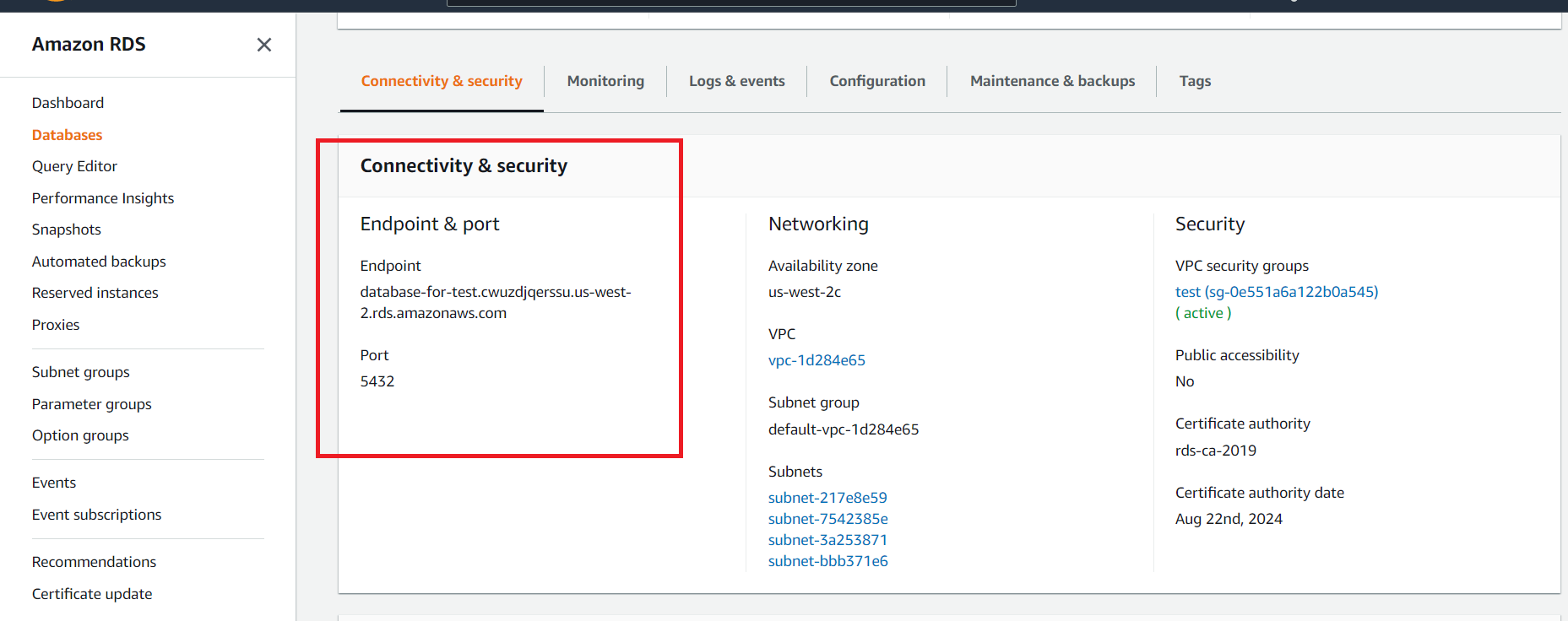
Після чого ми можемо відкрити PostgreSQL консоль із консолі нашого інстансу:
psql --host=<DB instance endpoint> --port=<port> --username=<master username> --password
Створюємо користувача і базу, ми це вже вміємо робити.
Припустимо, у нас знову user - myuser, password - mypass, db - mydb;
Як підключити RDS до застосунку? Додаємо URL у змінні оточення, і база буде підключена.
Не забуваємо провести міграції, ми підключили нову базу!
IAM
Для використання S3 Bucket нам необхідний спеціальний юзер, якого ми можемо створити в IAM
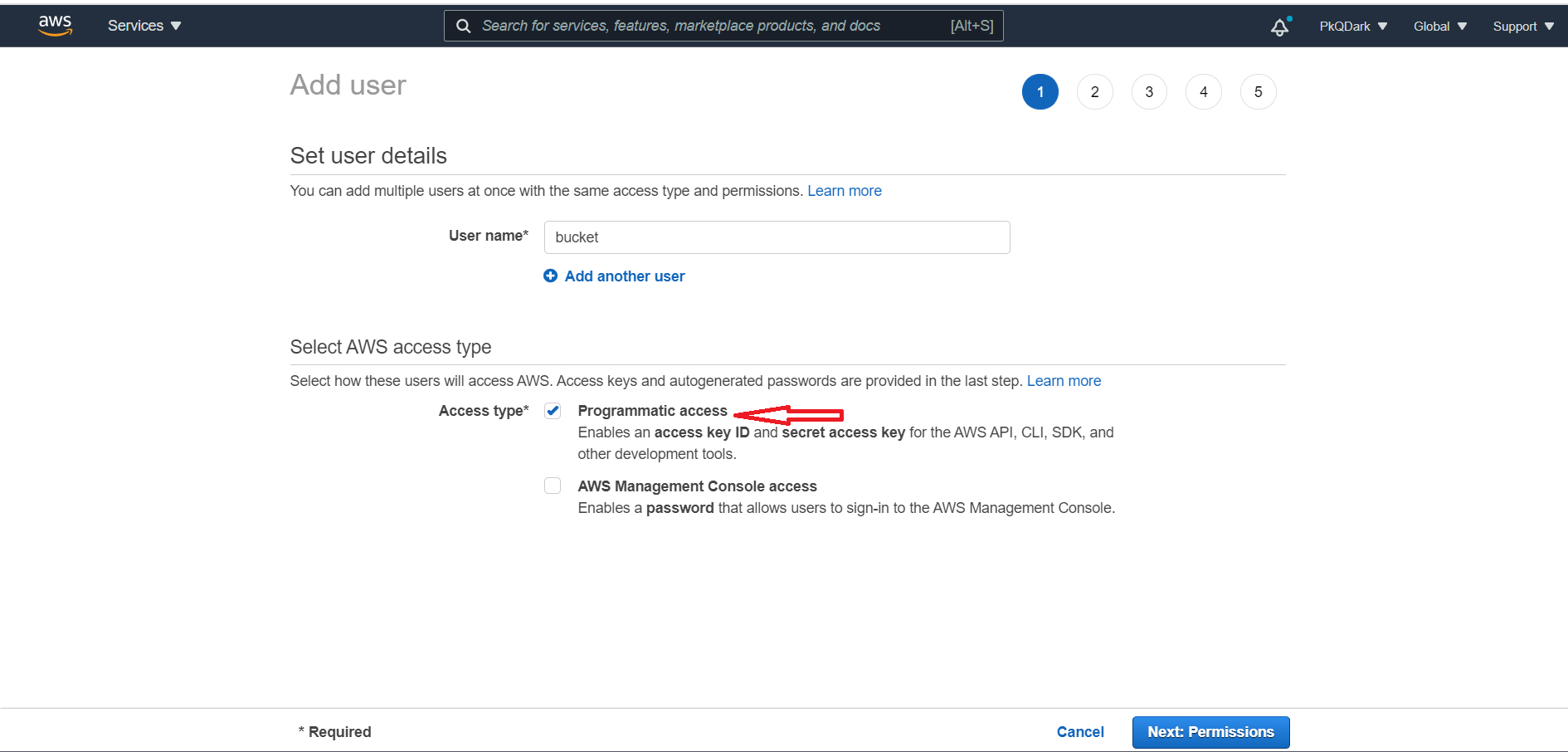
Вибираємо Programmatic access, наш користувач не буде заходити в налаштування, тільки генерувати токен.
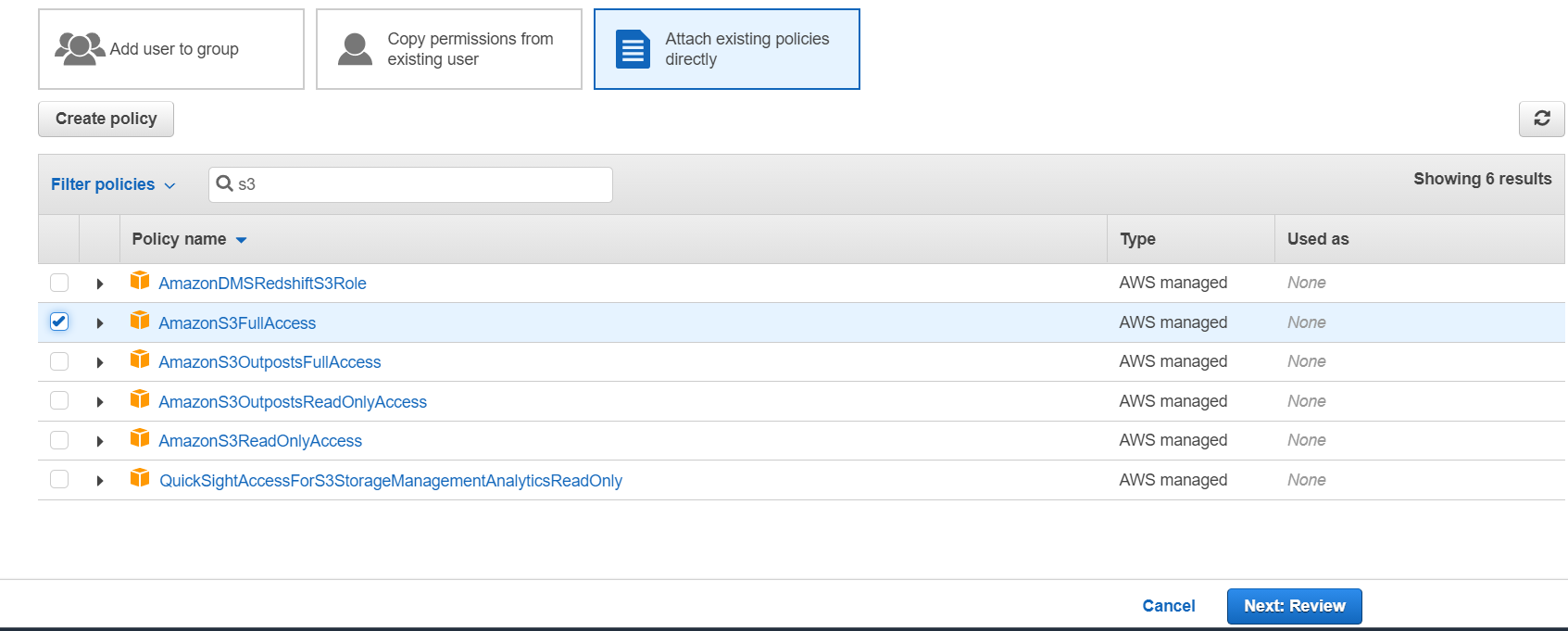
Додаємо користувачеві повні права на S3 Bucket.
Обов’язково зберігаємо ключі від користувача.
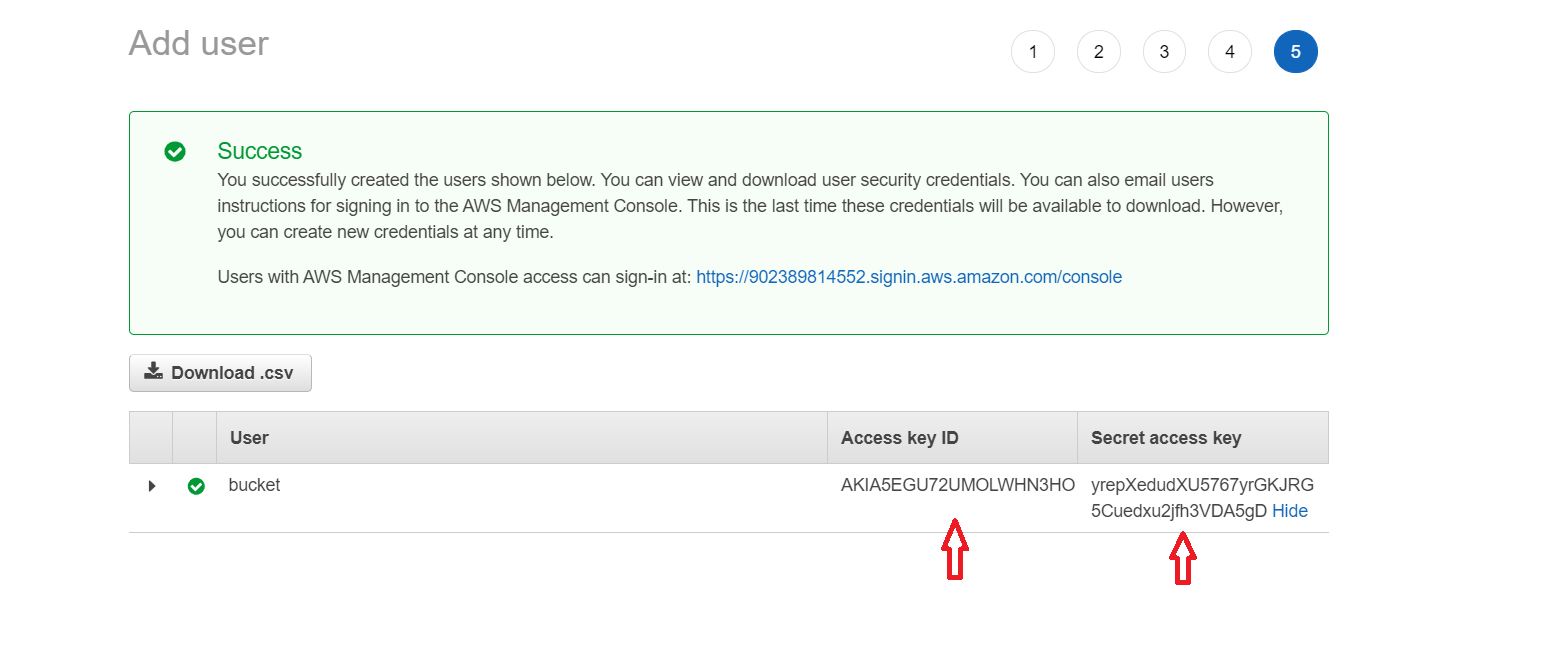
Ніколи, ні, НІКОЛИ не викладаємо ці ключі на git (вsettings.py або де-небудь ще). Amazon моніторить абсолютно весь інтернет. :) І якщо ваші ключі опиняться у відкритому репозиторії, користувач буде миттєво заблокований, а власнику акаунта напишуть про це лист і зателефонують, щоб попередити.
S3 Bucket
Створимо новий S3 Bucket у регіоні us-east-1, з ним найпростіше налаштування.
З повністю закритим доступом до файлів.
Для використання S3 у нашому проєкті потрібно доставити Python модулі:
pip install django-storages boto3
Якщо ви використовуватимете S3 і локально, то можна встановити пакети і локально, але найчастіше для локальних тестів зовнішні сервіси не використовуються.
Для використання потрібно додати storages в INSTALLED_APPS:
INSTALLED_APPS = [
...,
'storages',
]
після чого достатньо додати налаштування:
# Optional
AWS_S3_OBJECT_PARAMETERS = {
'Expires': 'Thu, 31 Dec 2099 20:00:00 GMT',
'CacheControl': 'max-age=94608000',
}
# Required
AWS_STORAGE_BUCKET_NAME = 'BUCKET_NAME'
AWS_S3_REGION_NAME = 'REGION_NAME' # e.g. us-east-2
AWS_ACCESS_KEY_ID = 'xxxxxxxxxxxxxxxxxxxxxxxxxx'
AWS_SECRET_ACCESS_KEY = 'yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy'
# НЕ ВПИСУЙТЕ САМІ КЛЮЧІ, ТІЛЬКИ os.environ.get('SOME_KEY')
# Tell the staticfiles app to use S3Boto3 storage when writing the collected static files (when
# you run `collectstatic`).
STATICFILES_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage'
Цього достатньо, щоб команда collectstatic збирала всю статику в S3 Bucket від Amazon, а template tag static генерував URL з параметрами безпеки, отримати таку статику просто так не можна.
AWS_S3_OBJECT_PARAMETERS - необов’язковий параметр, щоб вказати налаштування об’єктів, параметрів досить багато.
Але за такого налаштування вся статика буде просто складена в S3 Bucket, як на звалищі, куди ж ми помістимо медіа?
Щоб скласти статику і медіа в один S3 Bucket, потрібно створити нові класи для storages, де вказати папки для зберігання різних типів даних.
Створимо файл custom_storages.py на одному рівні з ``settings.py`.
# custom_storages.py
from django.conf import settings
from storages.backends.s3boto3 import S3Boto3Storage
class StaticStorage(S3Boto3Storage):
location = settings.STATICFILES_LOCATION
class MediaStorage(S3Boto3Storage):
location = settings.MEDIAFILES_LOCATION
А вsettings.py вкажемо:
# settings.py
STATICFILES_LOCATION = 'static'
STATICFILES_STORAGE = 'custom_storages.StaticStorage'
MEDIAFILES_LOCATION = 'media'
DEFAULT_FILE_STORAGE = 'custom_storages.MediaStorage'
Цього цілком достатньо, щоб команда collectstatic зібрала всю статику в папку static на S3 Bucket, а будь-які завантажені користувачами файли - у папку media.
Додаємо всі необхідні змінні оточення, запускаємо collectstatic, переконуємося, що все зібрано правильно, і статика працює, так само можемо спробувати завантажити що-небудь і переконатися, що медіа вантажиться правильно (якщо такий функціонал закладено в проєкт).
За такого підходу Nginx не обробляє статику і медіа, а значить, що ці рядки можна не вносити (або видалити з конфіга).
Route 53
Route 53 - це сервіс, де ви можете зареєструвати домен і прив’язати його до вашої IP-адреси, щоб використовувати URL, а не IP.
Я заздалегідь купив домен a-level-test.com :) Тому, якщо я відкрию вкладку Hosted zones, то побачу:
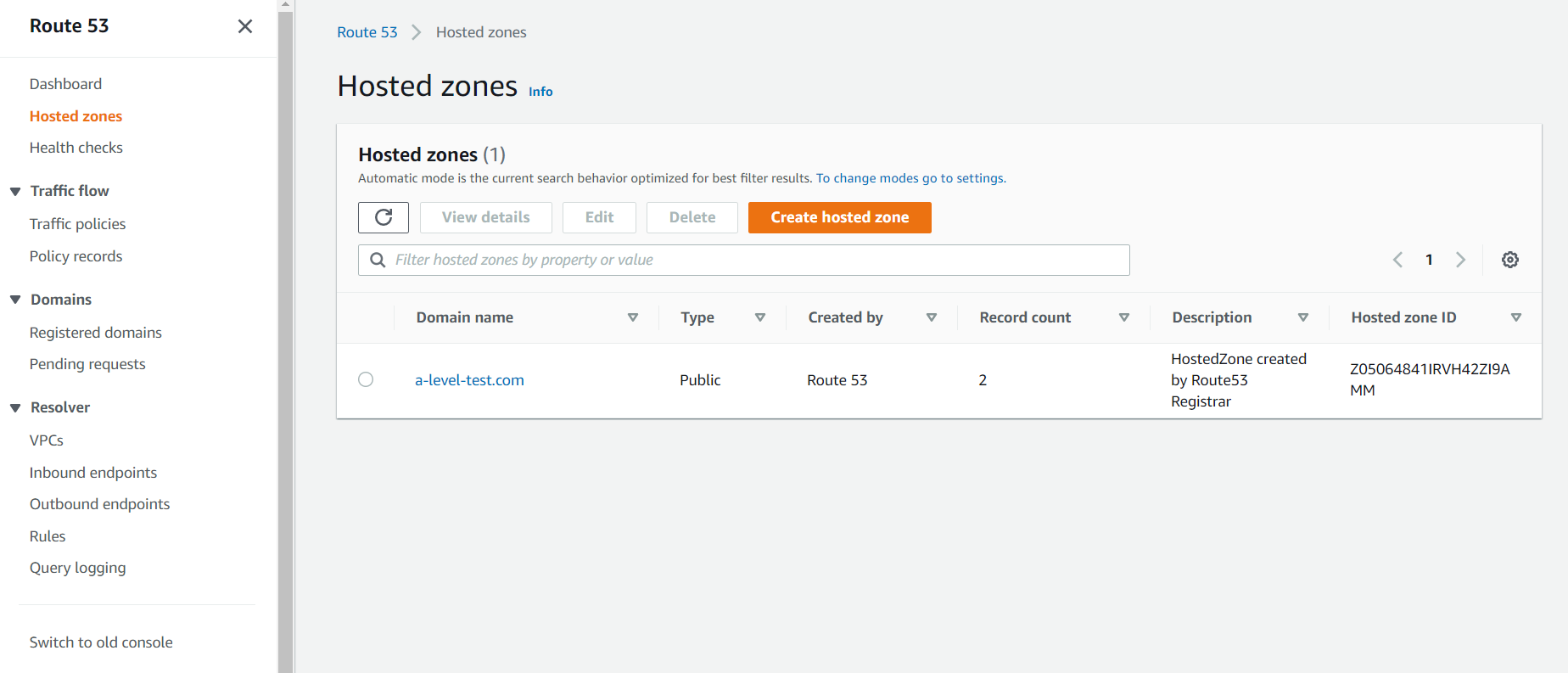
Створимо новий запис у hosted zone:
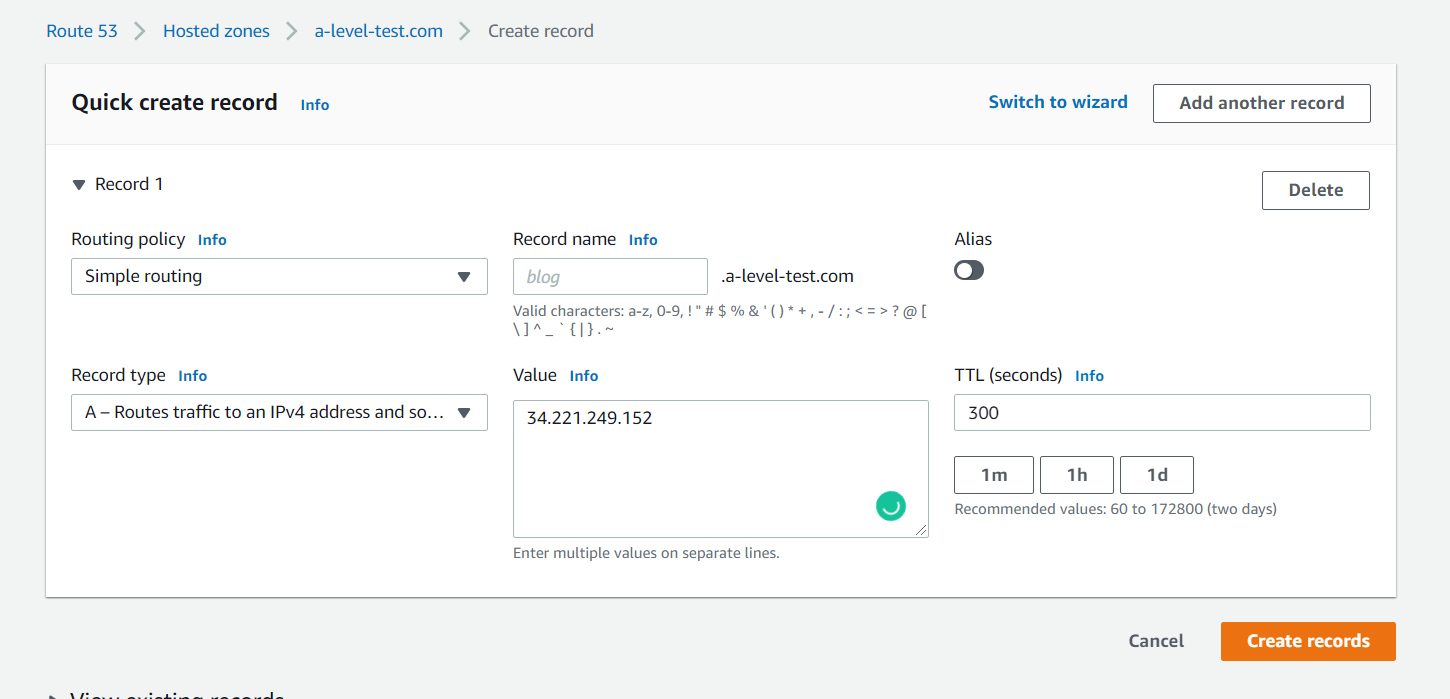
У полі value я вказав IP, який видав мені Amazon до мого інстансу.
У settings.py в ALLOWED_HOSTS потрібно додати новий URL.
...
DEBUG = False
ALLOWED_HOSTS = ['a-level-test.com']
...
Пулимо новий код, перезапускаємо gunicorn:
```sudo systemctl restart gunicorn``
Після цього мені потрібно оновити Nginx і поміняти там server_name;
server {
listen 80;
server_name a-level-test.com;
location / {
include proxy_params;
proxy_pass http://unix:/home/ubuntu/deployment/r/gunicorn.sock;
}
}
Перезапускаємо Nginx:
sudo service nginx restart
Відкриваємо URL, переконуємося, що все працює і статика не загубилася.
HTTPS. Certbot
Наше з’єднання працює, але при цьому абсолютно не захищене. Чому ми не зробили його безпечним раніше? Все просто, сертифікат для ввімкнення https прив’язується до URL, а не до IP-адреси. Зробити це можна дуже просто і в практично автоматичному режимі.
Для початку необхідно доставити на сервер деякі модулі:
sudo apt install certbot python3-certbot-nginx
І виконати команду:
sudo certbot --nginx -d a-level-test.com
Після параметра -d вказується server_name з Nginx;
Certbot запитає у вас пошту, якщо це перший запуск, попросить прийняти умови і вказати, чи редиректувати небезпечне з’єднання в безпечне чи ні, все залежить від ваших умов. Він автоматично замінить і перезапустить конфігурацію Nginx:
server {
server_name a-level-test.com;
location / {
include proxy_params;
proxy_pass http://unix:/home/ubuntu/deployment/r/gunicorn.sock;
}
listen 443 ssl; # managed by Certbot
ssl_certificate /etc/letsencrypt/live/a-level-test.com/fullchain.pem; # managed by Certbot
ssl_certificate_key /etc/letsencrypt/live/a-level-test.com/privkey.pem; # managed by Certbot
include /etc/letsencrypt/options-ssl-nginx.conf; # managed by Certbot
ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem; # managed by Certbot
}
server {
if ($host = a-level-test.com) {
return 301 https://$host$request_uri;
} # managed by Certbot
listen 80;
server_name a-level-test.com;
return 404; # managed by Certbot
}
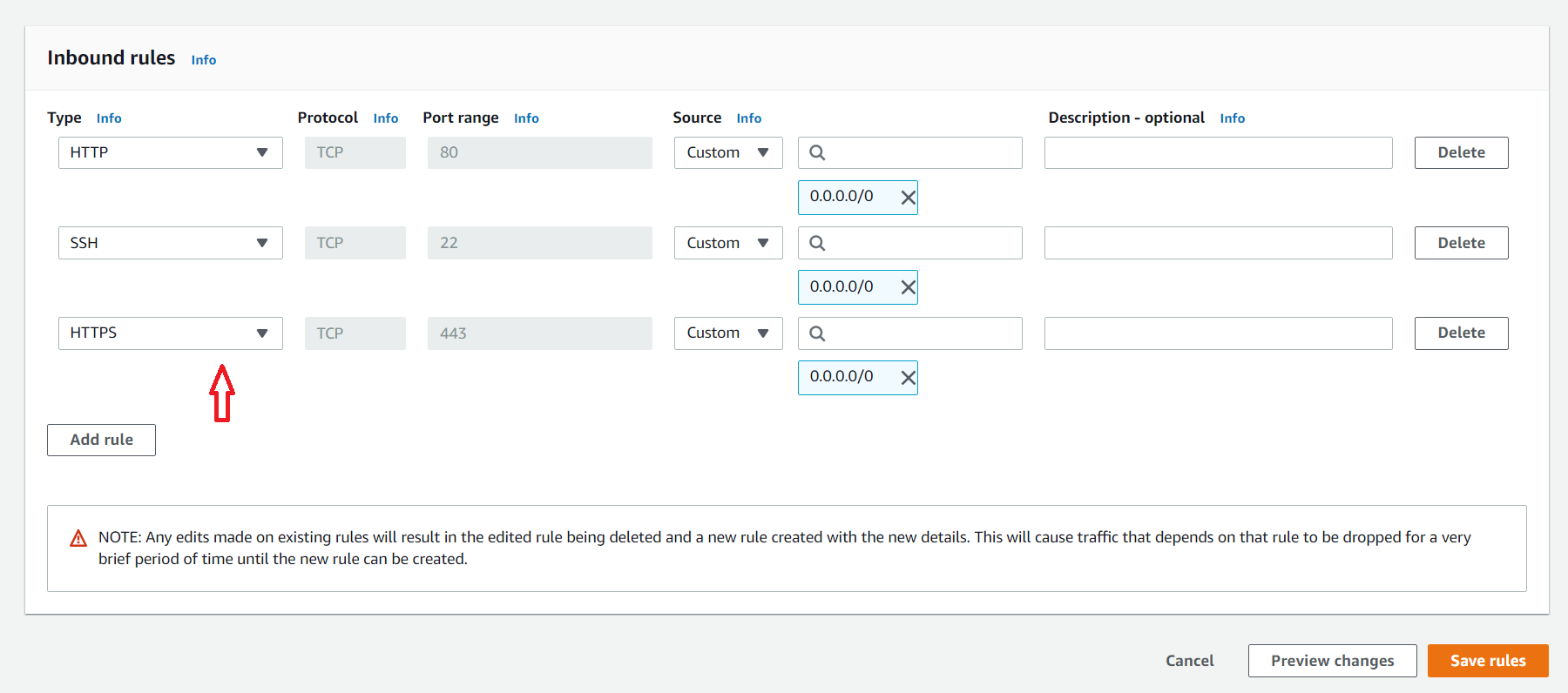
Відкрити на Amazon 443 порт
Не забуваємо відкрити порт номер 443 для нашого інстансу.
Усе, пробуємо відкрити сайт і бачимо, що він тепер безпечний.
Автооновлення сертифіката
Сертифікати Let’s Encrypt дійсні лише протягом 90 днів. Це зроблено для стимулювання користувачів до автоматизації процесу оновлення сертифікатів. Встановлений нами пакет certbot виконує це автоматично, додаючи таймер systemd, який запускатиметься двічі на день і автоматично подовжуватиме всі сертифікати, що закінчуються менш ніж через 30 днів.
Щоб протестувати процес оновлення, можна зробити запуск “вхолосту” за допомогою certbot:
sudo certbot renew --dry-run
Якщо помилок немає, все нормально. Certbot буде продовжувати ваші сертифікати, коли це буде потрібно, і перезавантажувати Nginx для активації змін. Якщо процес автоматичного оновлення коли-небудь не виконається, то Let’s Encrypt. надішле повідомлення на вказану вами адресу електронної пошти з попередженням про те, що термін дії сертифіката добігає кінця.